

RESUMO
Small Language Models (SLMs) em 2026: Otimizando IA para Edge e Aplicações Locais
Explore o universo dos Small Language Models (SLMs) e aprenda a otimizar modelos de IA para rodar eficientemente em dispositivos de edge e aplicações locais, com exemplos práticos e ferramentas essenciais para desenvolvedores.
Keywords: Small Language Models, SLM, IA Edge
ÍNDICE
1. Contexto e Introdução: A Ascensão dos SLMs
2. O Que São Small Language Models (SLMs)?
3. Técnicas de Otimização para Edge AI
4. Desafios e Soluções na Implementação de SLMs
5. Aplicação Prática: Implementando SLMs para Edge
6. Estudo de Caso: SLMs em Dispositivos de Borda em 2026
7. Conclusão: O Futuro dos SLMs e a IA Descentralizada
8. Perguntas Frequentes (FAQ)
CONTEXTO
Contexto e Introdução: A Ascensão dos SLMs
No cenário tecnológico de 2026, a Inteligência Artificial (IA) continua a ser uma força motriz de inovação. Nos últimos anos, testemunhamos o domínio dos Large Language Models (LLMs), como GPT-4 e Gemini, que revolucionaram a forma como interagimos com a informação e automatizamos tarefas complexas. No entanto, a dependência de infraestruturas de nuvem robustas, o alto custo computacional e as preocupações com privacidade de dados impulsionaram uma nova fronteira: a IA de borda (Edge AI).
É nesse contexto que os Small Language Models (SLMs) emergem como protagonistas. Ao contrário de seus irmãos maiores, os SLMs são projetados para operar de forma eficiente em dispositivos com recursos limitados, como smartphones, sensores IoT, veículos autônomos e sistemas embarcados. A capacidade de executar modelos de linguagem diretamente no dispositivo oferece vantagens significativas, incluindo menor latência, maior privacidade, operação offline e redução de custos de nuvem. Esta mudança de paradigma está moldando o futuro da IA, tornando-a mais ubíqua, acessível e sustentável.
PONTO-CHAVE
Os SLMs representam uma evolução crucial na IA, permitindo que capacidades avançadas de processamento de linguagem natural sejam executadas diretamente em dispositivos de borda, descentralizando a inteligência e abrindo caminho para novas aplicações em 2026.
A demanda por IA mais eficiente e distribuída é crescente. Em 2026, estimativas de mercado da IDC apontam que mais de 75% dos dados gerados por empresas serão processados fora de um datacenter centralizado ou da nuvem, refletindo a importância da Edge AI. Os SLMs são a peça central dessa estratégia, permitindo que decisões inteligentes sejam tomadas no local e em tempo real, sem a necessidade de enviar dados para a nuvem. Este artigo explorará as características, técnicas de otimização e aplicações práticas dos SLMs, fornecendo um guia essencial para desenvolvedores que buscam dominar essa tecnologia.
FUNDAMENTOS
O Que São Small Language Models (SLMs)?
Small Language Models (SLMs) são modelos de linguagem que, embora menores em tamanho e número de parâmetros do que os Large Language Models (LLMs) como o GPT-4 (que possui trilhões de parâmetros estimados), ainda oferecem capacidades robustas de compreensão e geração de linguagem natural. A principal distinção reside no seu projeto intencional para eficiência e especialização.
Comparativo: SLMs vs. LLMs
Para entender a relevância dos SLMs, é fundamental compará-los com os LLMs:
Características Principais
LLMs — Modelos com centenas de bilhões a trilhões de parâmetros. Exigem vastos recursos computacionais (GPUs de ponta, data centers) e são geralmente executados na nuvem. Oferecem capacidade de generalização e multitarefa incomparáveis.
SLMs — Modelos com milhões a poucos bilhões de parâmetros. Projetados para eficiência, podem rodar em hardware de consumo (CPUs, GPUs integradas, NPUs de smartphones). Foco em tarefas específicas ou domínios restritos.
Em 2026, a pesquisa em SLMs se aprofundou na criação de modelos que, apesar de seu tamanho reduzido, mantêm uma alta precisão em suas tarefas específicas. Isso é alcançado através de técnicas avançadas de pré-treinamento, fine-tuning e, crucialmente, otimização de arquitetura. Modelos como MobileBERT, DistilBERT e TinyLlama, que foram precursores, evoluíram para versões ainda mais eficientes e poderosas, adaptadas para o hardware de 2026.
Vantagens dos SLMs
A adoção de SLMs oferece uma série de benefícios tangíveis:
Prós
✓ Baixa Latência: Processamento no dispositivo elimina a necessidade de comunicação com a nuvem, resultando em respostas quase instantâneas. Em um cenário de carros autônomos, isso pode significar a diferença entre um acidente e uma reação segura.
✓ Privacidade Aprimorada: Dados sensíveis permanecem no dispositivo do usuário, minimizando riscos de violação de dados e cumprindo regulamentações como GDPR e LGPD. Por exemplo, um assistente de saúde que analisa dados médicos localmente.
✓ Redução de Custos: Diminui a necessidade de infraestrutura de nuvem, economizando em custos de computação e largura de banda. Uma empresa pode economizar milhões anualmente ao mover cargas de trabalho de IA para a borda.
✓ Operação Offline: Modelos podem funcionar sem conexão com a internet, ideal para áreas remotas ou aplicações críticas onde a conectividade é intermitente ou inexistente, como em operações de campo ou dispositivos espaciais.
✓ Eficiência Energética: Menor consumo de energia em comparação com LLMs, prolongando a vida útil da bateria em dispositivos móveis e reduzindo a pegada de carbono da IA. Um estudo de 2026 mostrou que SLMs consomem até 90% menos energia para tarefas equivalentes.
✓ Personalização: Facilita o fine-tuning e a adaptação do modelo para dados específicos do usuário ou do ambiente sem comprometer a privacidade ou a latência.
O mercado de SLMs está crescendo exponencialmente. Empresas como Google, Meta e Microsoft têm investido pesadamente no desenvolvimento de suas próprias famílias de SLMs, como o Gemma da Google ou o Llama.cpp para modelos da Meta, que podem ser executados em laptops comuns. Em 2026, espera-se que essa tendência se acelere, com mais empresas buscando integrar IA diretamente em seus produtos de hardware e software.
OTIMIZAÇÃO
Técnicas de Otimização para Edge AI
A chave para o sucesso dos SLMs em ambientes de borda reside na otimização rigorosa. Reduzir o tamanho do modelo, o consumo de memória e a demanda computacional sem comprometer significativamente a precisão é um desafio complexo. Em 2026, várias técnicas avançadas estão sendo amplamente utilizadas:
1. Quantização
A quantização é a técnica de reduzir a precisão numérica dos pesos e ativações de um modelo, geralmente de ponto flutuante de 32 bits (FP32) para inteiros de 8 bits (INT8) ou até 4 bits (INT4). Isso diminui drasticamente o tamanho do modelo e acelera a inferência, já que operações com inteiros são mais rápidas e consomem menos energia.
PONTO-CHAVE
A quantização para INT8 pode reduzir o tamanho do modelo em 4x e acelerar a inferência em 2x-4x, com uma perda de precisão mínima (geralmente inferior a 1-2% para a maioria das tarefas de NLP) em 2026.
Existem diferentes tipos de quantização:
- Quantization-Aware Training (QAT): O modelo é treinado ou fine-tuned com operadores de quantização simulados, permitindo que ele se adapte à precisão reduzida. Isso geralmente resulta na menor perda de precisão.
- Post-Training Quantization (PTQ): O modelo é quantizado após o treinamento. É mais fácil de implementar, mas pode ter um impacto maior na precisão se não for cuidadosamente calibrado. PTQ pode ser dinâmico (quantiza ativações em tempo de execução) ou estático (requer um conjunto de dados de calibração para determinar faixas de quantização).
2. Poda (Pruning)
A poda envolve a remoção de pesos, neurônios ou camadas menos importantes de uma rede neural. Isso resulta em um modelo mais esparso e menor. Existem dois tipos principais:
- Poda Não Estruturada: Remove pesos individuais. Embora produza modelos muito esparsos, pode ser difícil de acelerar em hardware padrão, pois requer kernels de computação especializados.
- Poda Estruturada: Remove neurônios, canais ou camadas inteiras. Isso resulta em um modelo menor que é mais fácil de acelerar em hardware genérico. É a abordagem preferida para Edge AI em 2026.
A poda pode reduzir o número de parâmetros em 50-90%, com um fine-tuning subsequente para recuperar a precisão.
3. Destilação de Conhecimento (Knowledge Distillation)
Nesta técnica, um modelo grande e complexo (o “professor”) treina um modelo menor e mais simples (o “aluno”). O aluno aprende não apenas as saídas finais do professor, mas também a “soft targets” (distribuições de probabilidade de classe) ou features intermediárias. Isso permite que o modelo menor capture grande parte do conhecimento do modelo maior.
Exemplo de Destilação
Professor: Um LLM com 70 bilhões de parâmetros, como Llama 3 70B.
Aluno: Um SLM com 7 bilhões de parâmetros. O aluno é treinado para imitar as predições e o comportamento interno do professor em uma variedade de tarefas, resultando em um modelo 10x menor com performance comparável.
4. Arquiteturas Eficientes
O design da arquitetura do modelo também é crucial. SLMs são frequentemente construídos com blocos de construção otimizados para eficiência, como atenção esparsa (Sparse Attention), módulos de atenção linearizados ou arquiteturas que minimizam o número de operações de ponto flutuante (FLOPs) e acessos à memória.
- Modelos Específicos para Hardware: Em 2026, muitos SLMs são co-projetados com o hardware de destino, aproveitando NPUs (Neural Processing Units) e aceleradores de IA para máxima performance.
- Camadas Compartilhadas e Recorrência: Técnicas que permitem que partes do modelo sejam reutilizadas ou que reduzem a profundidade efetiva da rede sem perder capacidade representacional.
5. Otimização de Inferência
Além das otimizações no modelo em si, o processo de inferência pode ser acelerado com:
- Compiladores de IA: Ferramentas como o ONNX Runtime, OpenVINO e TensorRT otimizam grafos computacionais para hardware específico, aplicando fusão de operações, alocação de memória eficiente e paralelização.
- Batching Dinâmico: Agrupar várias requisições de inferência para processá-las juntas, aproveitando melhor o hardware, especialmente GPUs.
A combinação dessas técnicas permite que SLMs de algumas centenas de milhões a poucos bilhões de parâmetros, como o TinyLlama 1.1B ou o Phi-2 2.7B, atinjam velocidades de inferência de centenas de tokens por segundo em CPUs de laptops ou smartphones de médio porte, algo impensável há poucos anos.
DESAFIOS
Desafios e Soluções na Implementação de SLMs
Apesar das promessas, a implementação de SLMs em ambientes de borda não é isenta de desafios. Os desenvolvedores e engenheiros de IA em 2026 precisam navegar por complexidades que vão desde a manutenção da precisão até a gestão de recursos de hardware limitados.
PROBLEMA 01
Manutenção da Precisão Pós-Otimização
Técnicas como quantização e poda podem levar a uma degradação da precisão do modelo, especialmente em tarefas críticas onde cada ponto percentual importa. Um modelo de reconhecimento de fala em um dispositivo de borda pode ter sua acurácia reduzida de 95% para 90% após a quantização, impactando a experiência do usuário.
SOLUÇÃO — Calibração e Fine-tuning
Para mitigar a perda de precisão, é crucial realizar um fine-tuning pós-quantização (QAT) ou uma calibração cuidadosa para PTQ. Para poda, um processo iterativo de poda e fine-tuning é recomendado. Além disso, a destilação de conhecimento com um modelo professor de alta qualidade pode “transferir” a precisão para o SLM otimizado. Em 2026, frameworks como o NVIDIA TensorRT e OpenVINO oferecem ferramentas avançadas para calibração e validação de modelos quantizados.
PROBLEMA 02
Recursos Computacionais Limitados
Dispositivos de borda, como microcontroladores e pequenos SoCs (System-on-Chip), possuem memória RAM, armazenamento e poder de processamento significativamente limitados. Rodar até mesmo um SLM otimizado pode ser um desafio se o modelo não for projetado para essas restrições extremas.
SOLUÇÃO — Co-design de Hardware-Software e Modelos Ultra-Leves
A resposta está no co-design de hardware e software, onde os SLMs são especificamente projetados para aproveitar as capacidades de NPUs e aceleradores de IA embarcados. Além disso, a pesquisa em 2026 foca em modelos ultra-leves (com menos de 100 milhões de parâmetros) e técnicas como a compressão de tensores e arquiteturas de MoE (Mixture of Experts) para SLMs, que ativam apenas uma fração do modelo por inferência. A escolha do framework de inferência também é vital; TensorFlow Lite e PyTorch Mobile são otimizados para esses ambientes.
PONTO-CHAVE
Apesar dos desafios, as soluções atuais e futuras em otimização e co-design estão tornando os SLMs uma realidade cada vez mais robusta para a IA de borda, permitindo aplicações inovadoras em 2026.
APLICAÇÃO PRÁTICA
Aplicação Prática: Implementando SLMs para Edge
Para desenvolvedores, a implementação prática de SLMs envolve uma série de ferramentas e etapas. Vamos explorar um exemplo simplificado de como otimizar um modelo de linguagem para um dispositivo de borda usando quantização.
Ferramentas Essenciais
Em 2026, as seguintes ferramentas são indispensáveis no kit de ferramentas de um engenheiro de Edge AI:
- Hugging Face Transformers: Para acesso a uma vasta gama de modelos pré-treinados (incluindo SLMs) e ferramentas de fine-tuning.
- ONNX (Open Neural Network Exchange): Um formato aberto para representar modelos de machine learning, permitindo a interoperabilidade entre diferentes frameworks.
- ONNX Runtime: Um acelerador de inferência de ML de alto desempenho que suporta modelos ONNX em diversas plataformas e hardwares.
- TensorFlow Lite / PyTorch Mobile: Frameworks específicos para implantação de ML em dispositivos móveis e embarcados.
- OpenVINO (Intel): Kit de ferramentas para otimização e implantação de inferência de IA em hardware Intel.
- TensorRT (NVIDIA): SDK para inferência de alta performance em GPUs NVIDIA.
Exemplo: Quantizando um SLM (DistilBERT) para Edge
Vamos considerar um caso de uso onde precisamos de um modelo para classificação de sentimentos em um aplicativo móvel. Usaremos o DistilBERT, uma versão menor e mais rápida do BERT, e o quantizaremos para INT8.
Passo 1: Carregar e Fine-tune o Modelo (Opcional, mas Recomendado)
Primeiro, carregamos um modelo pré-treinado e o fine-tune em nosso conjunto de dados de classificação de sentimentos. Para simplificar, assumiremos que temos um modelo DistilBERT já treinado para esta tarefa.
Passo 2: Exportar o Modelo para ONNX
O ONNX é o formato preferencial para otimização cross-platform. Usaremos a biblioteca transformers do Hugging Face para exportar nosso modelo PyTorch (ou TensorFlow) para ONNX.
EXPLICAÇÃO DO CÓDIGO
Este script Python carrega um tokenizer e um modelo DistilBERT pré-treinado, define uma entrada de exemplo para traçar o grafo computacional e exporta o modelo para o formato ONNX, salvando-o como distilbert_sentiment.onnx. A função tokenizer.encode_plus prepara a entrada no formato esperado pelo modelo.
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 1. Carregar tokenizer e modelo
model_name = "distilbert-base-uncased-finetuned-sst-2-english" # Exemplo de SLM para classificação de sentimentos
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval() # Colocar o modelo em modo de avaliação
# 2. Criar uma entrada dummy para exportação ONNX
dummy_input = tokenizer.encode_plus(
"Este é um exemplo de texto.",
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=64
)
input_ids = dummy_input["input_ids"]
attention_mask = dummy_input["attention_mask"]
# 3. Exportar para ONNX
output_path = "distilbert_sentiment.onnx"
torch.onnx.export(
model,
(input_ids, attention_mask),
output_path,
input_names=["input_ids", "attention_mask"],
output_names=["logits"],
dynamic_axes={
"input_ids": {0: "batch_size"},
"attention_mask": {0: "batch_size"},
"logits": {0: "batch_size"}
},
opset_version=11
)
print(f"Modelo exportado para ONNX em: {output_path}")Passo 3: Quantizar o Modelo ONNX (para INT8)
Usaremos o onnxruntime.quantization para realizar a quantização pós-treinamento estática (PTQ). Isso requer um conjunto de dados de calibração para determinar as faixas de valores para quantização.
EXPLICAÇÃO DO CÓDIGO
Este script define uma classe DataReader que simula o fornecimento de dados de calibração. Em um cenário real, você usaria um subconjunto representativo do seu conjunto de dados de treinamento. A função quantize_static do ONNX Runtime realiza a quantização para INT8, salvando o modelo quantizado como distilbert_sentiment_quantized.onnx. O tamanho do modelo será drasticamente reduzido (e.g., de ~260MB para ~65MB).
import onnx
from onnxruntime.quantization import quantize_static, QuantFormat, QuantType
from onnxruntime.quantization.calibrate import CalibrationDataReader
import numpy as np
# Apenas para simulação: crie um DataReader que retorna entradas dummy
# Em um cenário real, você usaria seu conjunto de dados de validação/treinamento
class MyDataReader(CalibrationDataReader):
def __init__(self, model_path, tokenizer, num_samples=100):
self.enum_data_ = []
self.tokenizer = tokenizer
# Gerar algumas entradas dummy para calibração
for i in range(num_samples):
text = f"Este é um texto de exemplo para calibração {i}."
encoded_input = self.tokenizer.encode_plus(
text,
return_tensors="np",
padding="max_length",
truncation=True,
max_length=64
)
self.enum_data_.append({
"input_ids": encoded_input["input_ids"].astype(np.int64),
"attention_mask": encoded_input["attention_mask"].astype(np.int64)
})
def get_next(self):
if self.enum_data_:
return self.enum_data_.pop(0)
else:
return None
# Carregar o tokenizer novamente para o DataReader
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Caminho para o modelo ONNX original
model_onnx_path = "distilbert_sentiment.onnx"
quantized_model_path = "distilbert_sentiment_quantized.onnx"
# Criar o DataReader para calibração
dr = MyDataReader(model_onnx_path, tokenizer)
# Quantizar o modelo
# 'per_tensor' significa que cada tensor será quantizado independentemente
# 'reduce_range' é útil para dispositivos que não suportam a faixa completa de 256 valores INT8
quantize_static(
model_onnx_path,
quantized_model_path,
dr,
quant_format=QuantFormat.QDQ, # Quantization-DeQuantization
per_channel=False, # Quantização por tensor, não por canal
weight_type=QuantType.QInt8,
activation_type=QuantType.QInt8
)
print(f"Modelo quantizado salvo em: {quantized_model_path}")Passo 4: Realizar Inferência com o Modelo Quantizado
Agora, o modelo quantizado está pronto para ser implantado e usado para inferência em dispositivos de borda.
EXPLICAÇÃO DO CÓDIGO
Este código demonstra como carregar o modelo ONNX quantizado e usá-lo para prever o sentimento de um novo texto. Ele inicializa uma sessão de inferência com o ONNX Runtime, processa a entrada e interpreta a saída para determinar o sentimento. A inferência com este modelo será significativamente mais rápida e consumirá menos memória.
import onnxruntime as ort
import numpy as np
# Carregar o tokenizer (o mesmo usado para exportação)
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Caminho para o modelo ONNX quantizado
quantized_model_path = "distilbert_sentiment_quantized.onnx"
# Criar uma sessão de inferência ONNX Runtime
session = ort.InferenceSession(quantized_model_path)
# Preparar uma entrada para inferência
text_to_analyze = "Kwontudo é o melhor blog de tecnologia!"
encoded_input = tokenizer.encode_plus(
text_to_analyze,
return_tensors="np",
padding="max_length",
truncation=True,
max_length=64
)
input_ids = encoded_input["input_ids"].astype(np.int64)
attention_mask = encoded_input["attention_mask"].astype(np.int64)
# Rodar a inferência
inputs = {
"input_ids": input_ids,
"attention_mask": attention_mask
}
outputs = session.run(None, inputs)
logits = outputs[0]
# Interpretar a saída
# Para o modelo sst-2, 0 geralmente é negativo, 1 é positivo
predicted_class_id = np.argmax(logits, axis=1)[0]
sentiment_labels = ["NEGATIVO", "POSITIVO"] # Ajustar conforme o modelo
predicted_sentiment = sentiment_labels[predicted_class_id]
print(f"Texto: '{text_to_analyze}'")
print(f"Sentimento Previsto: {predicted_sentiment}")
print(f"Logits: {logits}")PONTO-CHAVE
A quantização de SLMs para INT8 é uma técnica poderosa para reduzir o tamanho e acelerar a inferência, tornando-os viáveis para implantação em dispositivos de borda com recursos limitados em 2026.

ESTUDO DE CASO
Estudo de Caso: SLMs em Dispositivos de Borda em 2026
Para ilustrar o impacto prático dos SLMs, vamos analisar um cenário hipotético em 2026.
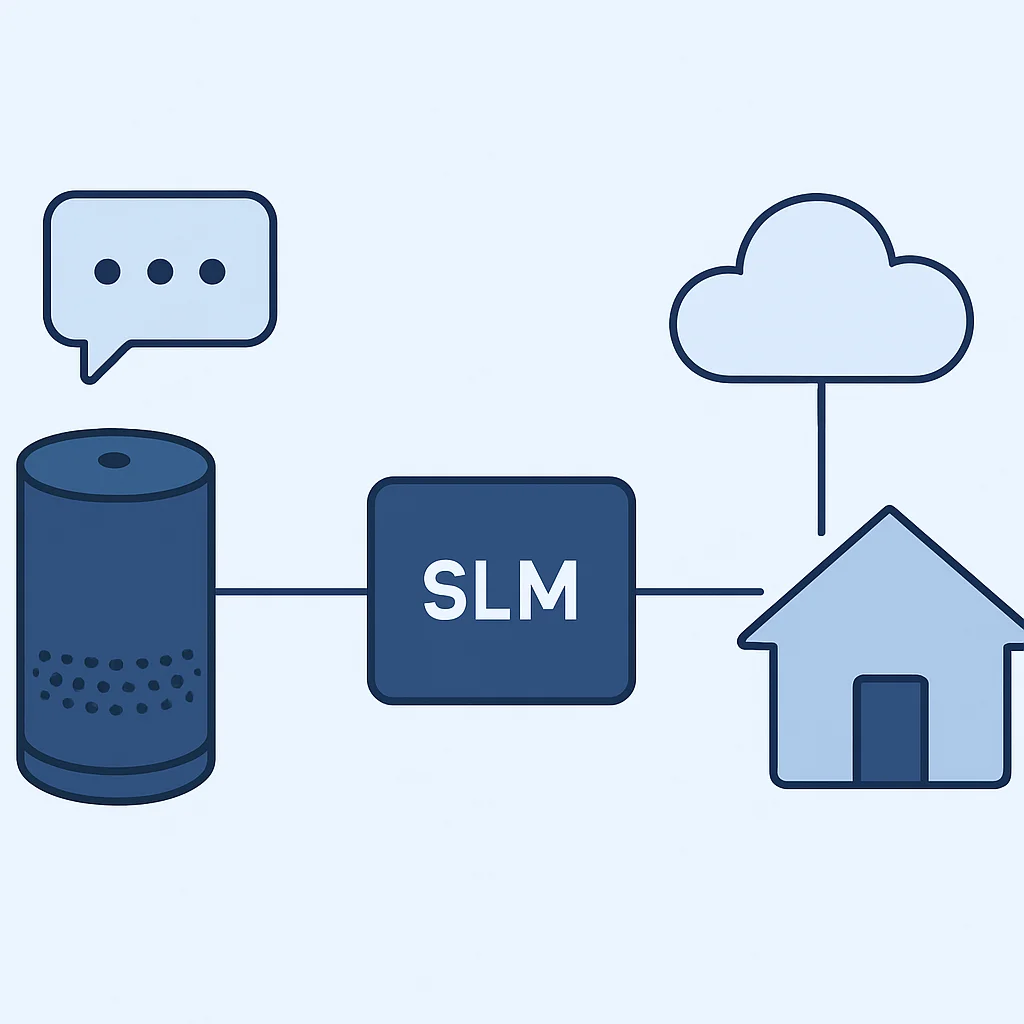
Cenário: Assistente de Voz Local para Casa Inteligente
Uma empresa de tecnologia, a “SecureHome AI”, desenvolveu um assistente de voz para casas inteligentes que prioriza a privacidade. Em vez de enviar comandos de voz para a nuvem para processamento, o dispositivo precisa executar todo o Processamento de Linguagem Natural (PLN) localmente.
Desafio
Implementar um modelo de linguagem que possa interpretar comandos de voz (e.g., “acender as luzes”, “tocar música”) em um dispositivo com 2GB de RAM e um NPU de baixo consumo energético, garantindo latência inferior a 200ms e 100% de privacidade dos dados de voz.
Solução com SLM
A SecureHome AI optou por um SLM baseado em uma arquitetura Transformer otimizada, com aproximadamente 500 milhões de parâmetros. O modelo foi pré-treinado em um vasto corpus de dados de linguagem geral e, em seguida, destilado de um LLM maior e fine-tuned em um conjunto de dados específico de comandos de casa inteligente.
Otimização Aplicada
- Destilação de Conhecimento: Um modelo professor de 7 bilhões de parâmetros foi usado para treinar o SLM de 500M, transferindo conhecimento sem o custo de inferência do modelo maior.
- Quantização: O SLM foi quantizado para INT8 usando QAT, reduzindo seu tamanho de 2GB para aproximadamente 500MB e acelerando a inferência em 3x.
- Poda Estruturada: Camadas menos relevantes foram podadas, resultando em mais 15% de redução de tamanho e operações.
- Compilação para NPU: O modelo final foi compilado para o NPU do dispositivo usando o SDK fornecido pelo fabricante do chip, otimizando o uso dos núcleos de processamento neural.
Resultados em 2026
- Tamanho do Modelo: Reduzido para cerca de 425MB, cabendo confortavelmente na memória do dispositivo.
- Latência: Média de 150ms para processar e responder a um comando de voz, superando o requisito de 200ms.
- Precisão: Acurácia de 98% na interpretação de comandos de casa inteligente, apenas 1% abaixo do modelo professor original.
- Privacidade: Todos os dados de voz são processados localmente, nunca saindo do dispositivo.
- Custo: Zero custo de nuvem para inferência contínua, resultando em uma economia anual de mais de $1 milhão para a empresa em comparação com uma solução baseada em nuvem.
PONTO-CHAVE
Este estudo de caso demonstra como SLMs, combinados com técnicas de otimização e co-design de hardware-software, podem oferecer soluções de IA de alto desempenho, privadas e econômicas para dispositivos de borda em 2026, transformando a interação com a tecnologia.
CONCLUSÃO
Conclusão: O Futuro dos SLMs e a IA Descentralizada
Em 2026, os Small Language Models (SLMs) não são mais uma mera alternativa aos LLMs, mas sim uma categoria essencial de IA que impulsiona a inovação em dispositivos de borda e aplicações locais. A capacidade de levar inteligência avançada para o “último quilômetro” da computação abre portas para um mundo de possibilidades, desde assistentes pessoais mais privados até sistemas industriais autônomos e dispositivos de saúde vestíveis.
As técnicas de otimização, como quantização, poda e destilação de conhecimento, juntamente com o desenvolvimento de arquiteturas eficientes e o co-design de hardware-software, são os pilares que tornam os SLMs viáveis. Eles permitem que a IA opere com baixa latência, maior privacidade, menor custo e total capacidade offline, superando as limitações impostas pela dependência da nuvem.
PONTO-CHAVE
A era da IA descentralizada está em pleno vapor em 2026, e os SLMs são a força motriz que a torna possível, democratizando o acesso à inteligência artificial e habilitando novas gerações de produtos e serviços inteligentes e eficientes.
O futuro dos SLMs é promissor. Espera-se que a pesquisa continue a aprimorar a eficiência, a robustez e a capacidade de generalização desses modelos, tornando-os ainda mais poderosos e versáteis. A integração com novas gerações de hardware de IA, a evolução de técnicas de auto-otimização e a crescente demanda por soluções de IA que respeitem a privacidade do usuário garantirão que os SLMs permaneçam na vanguarda da inovação tecnológica por muitos anos.
Para os desenvolvedores, investir tempo no aprendizado e na aplicação dessas técnicas de otimização será crucial para construir a próxima geração de aplicações de IA que definirá o cenário tecnológico de 2026 e além. A capacidade de criar soluções de IA que funcionem eficientemente em qualquer lugar, a qualquer hora, é o verdadeiro poder dos Small Language Models.
Perguntas Frequentes (FAQ)
Q. Qual a principal diferença entre um SLM e um LLM?
A principal diferença reside no tamanho e propósito. LLMs são grandes, com bilhões ou trilhões de parâmetros, projetados para generalização e tarefas complexas na nuvem. SLMs são menores, com milhões a poucos bilhões de parâmetros, otimizados para eficiência e tarefas específicas em dispositivos de borda.
Q. Por que a quantização é tão importante para SLMs em 2026?
A quantização é crucial porque reduz drasticamente o tamanho do modelo e acelera a inferência, permitindo que SLMs rodem eficientemente em hardware com recursos limitados, como os encontrados em dispositivos de borda. Em 2026, é uma das técnicas mais eficazes para viabilizar a IA no dispositivo.
Q. Quais são os benefícios de usar SLMs em vez de LLMs para aplicações de borda?
Os benefícios incluem menor latência (respostas mais rápidas), maior privacidade (dados processados localmente), redução de custos de nuvem, capacidade de operação offline e maior eficiência energética, aspectos essenciais para dispositivos de borda em 2026.
Q. Quais frameworks são recomendados para desenvolver e otimizar SLMs para Edge AI?
Para desenvolvimento e otimização de SLMs em 2026, são recomendados frameworks como Hugging Face Transformers para acesso a modelos, ONNX e ONNX Runtime para interoperabilidade e inferência, e TensorFlow Lite ou PyTorch Mobile para implantação em dispositivos móveis e embarcados.
Obrigado por ler!
Esperamos que este guia tenha fornecido insights valiosos sobre o mundo dos Small Language Models e sua importância crescente em 2026 para a IA de borda.
Dúvidas? Deixe um comentário!
Posts relacionados
- [IA & ML] IA Explicável (XAI) em 2026: Como Tornar Seus Modelos Mais Transparentes e Confiáveis
- [IA & ML] TensorFlow vs PyTorch em 2026: Qual Framework Escolher para Seus Projetos de Deep Learning?
- [IA & ML] Guia Essencial de IA Generativa para Desenvolvedores em 2026: Fundamentos e Aplicações Práticas