
RESUMO
[Backend] Estratégias de Cache para Otimizar Sua API em 2026: Redis, Memcached e Mais
Aprenda as melhores estratégias de cache para acelerar suas APIs, reduzir a carga do banco de dados e melhorar a experiência do usuário, explorando ferramentas como Redis e Memcached para alta performance.
Keywords: Backend, Cache, Redis, Memcached
ÍNDICE
1. Contexto e a Importância do Cache em 2026
2. Fundamentos do Cache e Seus Benefícios para APIs
3. Tipos e Estratégias de Cache para APIs Modernas
4. Ferramentas de Cache Distribuído: Redis vs. Memcached
5. Desafios Comuns e Soluções na Implementação de Cache
6. Guia Prático: Implementando Cache-Aside com Redis
7. Perguntas Frequentes sobre Cache em APIs
8. Conclusão e Perspectivas Futuras
CONTEXTO
Contexto e a Importância do Cache em 2026
No cenário tecnológico em constante evolução de 2026, a demanda por APIs de alta performance e baixa latência nunca foi tão crítica. Aplicações modernas, desde serviços de streaming de vídeo até plataformas de e-commerce e sistemas de gerenciamento de dados em tempo real, dependem fortemente de APIs que respondam instantaneamente, independentemente da carga de usuários ou da complexidade dos dados. A otimização de APIs não é mais um diferencial, mas uma necessidade fundamental para garantir a satisfação do usuário e a competitividade no mercado.
Com o aumento exponencial de dados e a proliferação de dispositivos conectados, os bancos de dados tradicionais frequentemente se tornam gargalos. Cada requisição a um endpoint de API que consulta diretamente o banco de dados impõe uma carga computacional significativa, aumentando o tempo de resposta e, em cenários de pico, levando à degradação do serviço ou até mesmo a falhas. É aqui que as estratégias de cache entram em jogo, atuando como um escudo protetor para seus bancos de dados e um acelerador para suas APIs.
Em 2026, a implementação de cache em APIs é uma prática padrão para desenvolvedores backend que buscam construir sistemas escaláveis e resilientes. Ao armazenar temporariamente cópias de dados frequentemente acessados em uma camada de memória mais rápida, o cache permite que as APIs sirvam respostas em milissegundos, em vez de centenas de milissegundos, ou até segundos. Isso não só melhora drasticamente a experiência do usuário, mas também reduz os custos operacionais ao diminuir a carga sobre a infraestrutura de banco de dados e computação.
A escolha da estratégia e da ferramenta de cache correta é crucial. Ferramentas como Redis e Memcached se estabeleceram como líderes de mercado devido à sua performance, flexibilidade e robustez. No entanto, entender quando e como aplicá-las, juntamente com outras técnicas de cache, é o que realmente define uma API de sucesso. Este artigo explorará em profundidade essas estratégias e ferramentas, fornecendo um guia completo para otimizar suas APIs em 2026.
PONTO-CHAVE
Em 2026, o cache em APIs é essencial para lidar com o volume de dados e as expectativas de baixa latência dos usuários, protegendo bancos de dados e garantindo a escalabilidade dos serviços.
ANÁLISE DETALHADA
Fundamentos do Cache e Seus Benefícios para APIs
Antes de mergulharmos nas ferramentas e estratégias, é fundamental compreender o que é o cache e por que ele é tão benéfico para o desempenho de APIs. Em sua essência, o cache é um mecanismo de armazenamento temporário que guarda cópias de dados que são caros de se obter ou calcular, mas que são frequentemente solicitados. Quando uma requisição por esses dados chega, o sistema verifica primeiro o cache. Se os dados estiverem lá (um “cache hit”), eles são retornados rapidamente. Caso contrário (um “cache miss”), os dados são buscados na fonte original (como um banco de dados), armazenados no cache para futuras requisições e então retornados.
Benefícios Primários do Cache em APIs
A implementação de cache oferece uma série de vantagens cruciais para qualquer arquitetura de API:
- Redução da Latência: O benefício mais direto. Dados no cache são acessados muito mais rápido do que dados em um banco de dados. Por exemplo, uma consulta complexa a um banco de dados pode levar 200-500ms, enquanto a leitura de um item do cache pode levar 1-5ms. Em um estudo de caso hipotético, uma API de e-commerce que implementou cache para seus produtos mais populares observou uma redução de 80% no tempo de resposta para essas requisições, caindo de 300ms para 60ms.
- Aumento do Throughput: Ao reduzir a carga em componentes mais lentos, como o banco de dados, o cache permite que a API processe um número muito maior de requisições por segundo. Um sistema que antes suportava 500 requisições/segundo pode facilmente escalar para 2000-5000 requisições/segundo com uma estratégia de cache eficiente, especialmente para dados estáticos ou semi-estáticos.
- Diminuição da Carga no Banco de Dados: O cache atua como um buffer, interceptando a maioria das requisições de leitura e evitando que elas cheguem ao banco de dados. Isso prolonga a vida útil do banco de dados, reduz a necessidade de scaling vertical e horizontal prematuro, e libera recursos para operações de escrita mais críticas.
- Melhora da Experiência do Usuário (UX): Respostas rápidas da API resultam em interfaces de usuário mais responsivas e menos frustração. Em aplicações móveis e web, uma diferença de 100ms no tempo de carregamento pode impactar diretamente as taxas de conversão e o engajamento do usuário.
- Redução de Custos: Menos carga no banco de dados e nos servidores de aplicação significa que menos recursos de computação são necessários, o que se traduz em economia de custos na infraestrutura em nuvem, especialmente em provedores como AWS, Google Cloud ou Azure, onde o custo é frequentemente baseado no uso de recursos.
PONTO-CHAVE
Um bom cache pode reduzir a latência de API de centenas para poucos milissegundos, aumentando o throughput em 3-5x e diminuindo a carga do banco de dados, resultando em melhor UX e economia de custos.
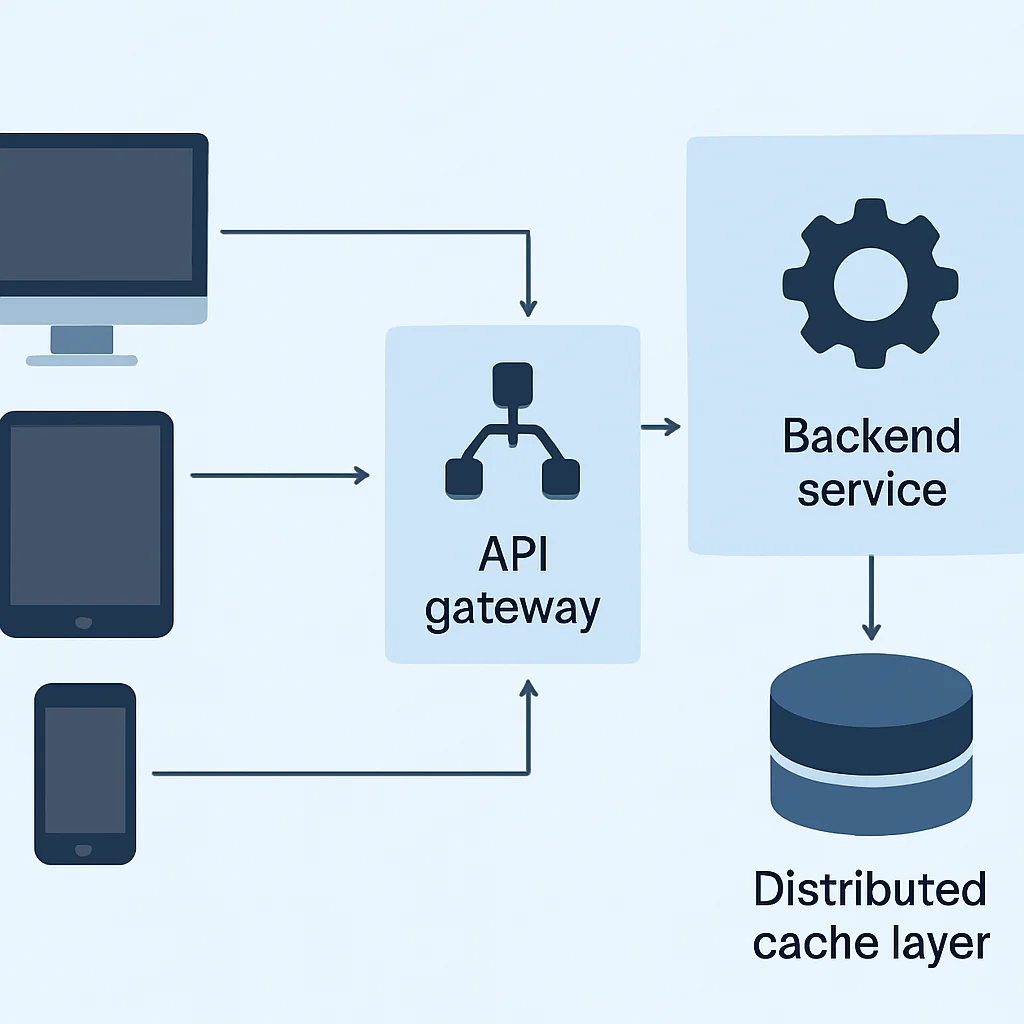
O diagrama acima ilustra como um sistema de cache se posiciona na arquitetura de uma aplicação moderna. As requisições dos clientes chegam ao backend, que primeiro consulta o cache. Apenas se os dados não estiverem no cache, a requisição prossegue para o banco de dados. Essa camada intermediária é o coração da otimização de performance.
ESTRATÉGIAS
Tipos e Estratégias de Cache para APIs Modernas
Existem diversas camadas e estratégias para implementar cache em uma API, cada uma com suas particularidades e casos de uso ideais. A escolha depende da natureza dos dados, da frequência de atualização e dos requisitos de consistência.
Tipos de Cache
- Cache no Cliente (Client-side Caching):
Implementado no navegador ou no aplicativo cliente. Utiliza cabeçalhos HTTP como
Cache-Control,ETageLast-Modifiedpara instruir o cliente a armazenar respostas por um determinado período. É ideal para dados que não mudam frequentemente, como imagens, arquivos CSS/JS ou dados de perfil de usuário estáticos. Reduz a carga no servidor e melhora a percepção de velocidade do usuário, pois as requisições nem chegam ao backend. - Cache no Servidor (Server-side Caching):
Implementado no lado do servidor, mais próximo da fonte de dados. Pode ser subdividido em:
- Cache In-memory (Local): Armazenado na memória de um único servidor de aplicação. É o mais rápido, mas não é compartilhado entre múltiplas instâncias da aplicação. Ferramentas como Guava Cache (Java) ou pacotes
lru-cache(Node.js) são exemplos. Adequado para dados de configuração ou resultados de cálculos intensivos que são específicos de uma instância. - Cache Distribuído: Armazenado em servidores dedicados de cache (como Redis ou Memcached) e acessível por todas as instâncias da aplicação. Essencial para microservices e arquiteturas escaláveis, pois garante que todas as instâncias vejam os mesmos dados em cache, evitando inconsistências. É o foco principal deste artigo.
- Cache de CDN (Content Delivery Network): Utilizado para distribuir conteúdo estático ou semi-estático geograficamente mais próximo dos usuários. CDNs armazenam cópias de recursos em servidores de borda (edge servers), reduzindo a latência para usuários em diferentes regiões. Embora frequentemente associado a arquivos estáticos, também pode ser usado para respostas de API que são globalmente idênticas para todos os usuários.
- Cache de Banco de Dados: Muitos sistemas de banco de dados e ORMs (Object-Relational Mappers) possuem seus próprios mecanismos de cache para consultas ou objetos. Embora útil, geralmente não substitui um cache distribuído para a camada de API, mas complementa-o.
- Cache In-memory (Local): Armazenado na memória de um único servidor de aplicação. É o mais rápido, mas não é compartilhado entre múltiplas instâncias da aplicação. Ferramentas como Guava Cache (Java) ou pacotes
Estratégias de Implementação de Cache
A forma como a aplicação interage com o cache é definida pela estratégia de implementação:
1. Cache-Aside (Lazy Loading)
Descrição — A aplicação é responsável por gerenciar o cache. Antes de buscar dados do banco de dados, ela verifica se os dados estão no cache. Se sim, retorna do cache. Se não, busca do banco de dados, armazena no cache e então retorna. Na escrita, a aplicação atualiza o banco de dados e invalida (remove) o item correspondente do cache.
Vantagens — Simples de implementar, o cache só armazena dados que são realmente solicitados. Resiliente a falhas do cache (a aplicação ainda pode ir ao DB).
Desvantagens — “Cache misses” iniciais (primeira requisição é lenta), potencial para inconsistência temporária entre cache e DB.
2. Read-Through
Descrição — O cache atua como um proxy para o banco de dados. A aplicação sempre consulta o cache. Se o item não estiver presente, o cache é responsável por buscar os dados do banco de dados, armazená-los e então retorná-los à aplicação.
Vantagens — Aplicação mais simples, pois não precisa gerenciar a lógica de busca no DB. Mais fácil de manter a consistência.
Desvantagens — Requer que o cache seja “inteligente” o suficiente para interagir com o DB. Menos flexibilidade na lógica de cache.
3. Write-Through
Descrição — Na escrita, os dados são primeiramente escritos no cache e, em seguida, o cache escreve os dados no banco de dados. A aplicação só recebe a confirmação após a escrita em ambos.
Vantagens — Garante que o cache esteja sempre consistente com o banco de dados, ideal para dados que precisam de alta consistência. Garante que os dados recém-escritos estejam imediatamente disponíveis no cache para leituras.
Desvantagens — Adiciona latência às operações de escrita, pois a escrita precisa ser confirmada em dois lugares. Pode ser mais complexo de implementar.
4. Write-Back (Write-Behind)
Descrição — Os dados são escritos no cache, e a confirmação é enviada imediatamente à aplicação. A escrita no banco de dados ocorre de forma assíncrona, em segundo plano.
Vantagens — Latência muito baixa para operações de escrita. Excelente para sistemas com alta taxa de escrita.
Desvantagens — Risco de perda de dados se o cache falhar antes que os dados sejam persistidos no banco de dados. Maior complexidade para garantir durabilidade e recuperação.
5. Refresh-Ahead
Descrição — O cache monitora a frequência de acesso aos itens e, antes que um item expire, ele é proativamente atualizado em segundo plano a partir do banco de dados. Isso visa evitar “cache misses” em itens populares.
Vantagens — Reduz significativamente a latência, pois os dados estão quase sempre frescos no cache. Melhora a experiência do usuário ao evitar o “thundering herd” de requisições ao DB em caso de expiração.
Desvantagens — Maior complexidade na implementação e gerenciamento. Pode consumir mais recursos do cache e do DB com atualizações proativas que talvez não sejam necessárias.
PONTO-CHAVE
A estratégia Cache-Aside é a mais comum e flexível, mas Write-Through garante consistência e Refresh-Ahead otimiza a latência para dados populares.
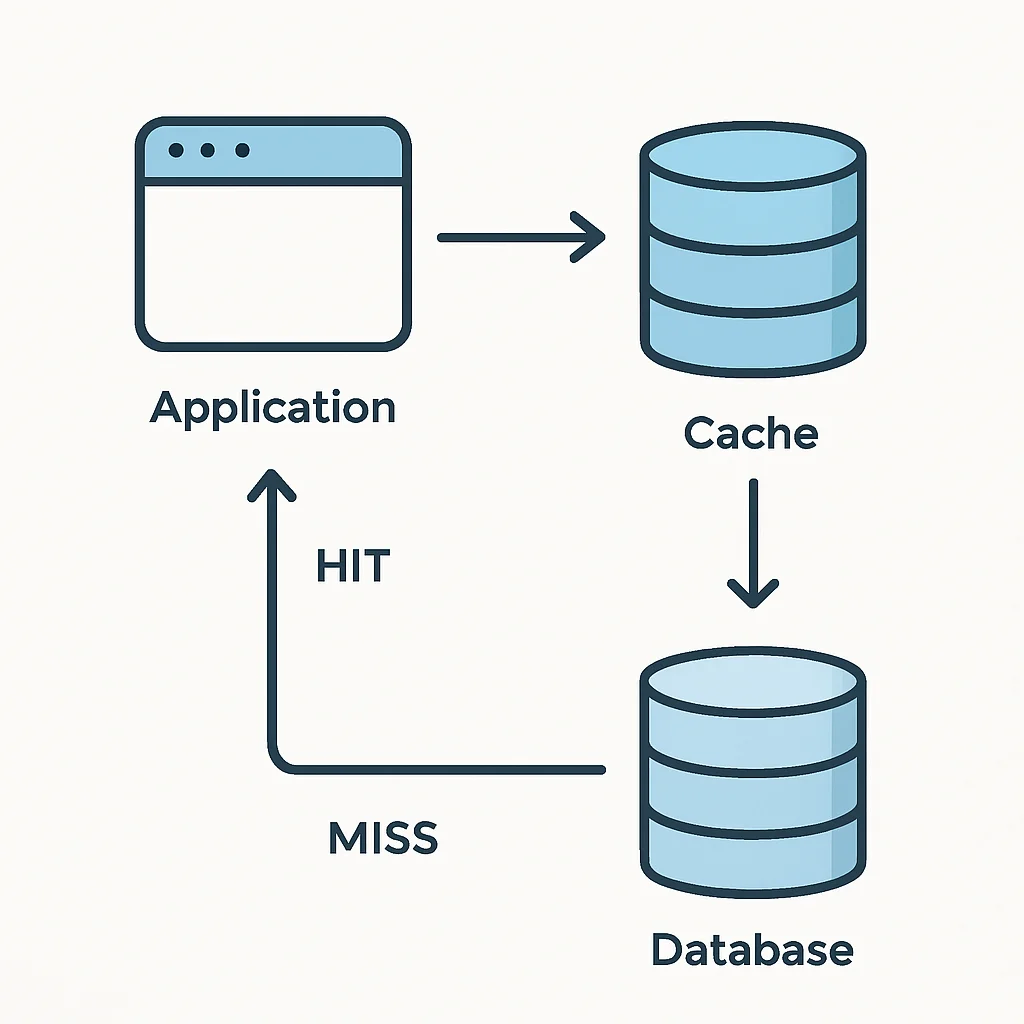
O fluxograma acima detalha o funcionamento da estratégia Cache-Aside, mostrando o caminho da requisição desde a aplicação até o retorno dos dados, com a lógica de verificação e preenchimento do cache.
FERRAMENTAS
Ferramentas de Cache Distribuído: Redis vs. Memcached
No domínio do cache distribuído, Redis e Memcached são os players dominantes. Ambos oferecem soluções de alta performance para armazenamento em memória, mas com filosofias e conjuntos de recursos distintos.
Redis (Remote Dictionary Server)
Redis é um armazenamento de estrutura de dados em memória de código aberto, usado como banco de dados, cache e message broker. É conhecido por sua versatilidade e desempenho excepcional.
- Estruturas de Dados Ricas: Além de simples pares chave-valor (strings), Redis suporta listas, conjuntos (sets), conjuntos ordenados (sorted sets), hashes, bitmaps, HyperLogLogs e streams. Isso o torna extremamente flexível para uma variedade de casos de uso além do cache puro, como filas de tarefas, placares de líderes em tempo real, contadores de visualização, etc.
- Persistência: Redis pode persistir dados no disco (RDB snapshots ou AOF – Append Only File), o que significa que os dados não são perdidos em caso de reinício do servidor. Isso é crucial para dados de cache que levam tempo para serem reconstruídos ou para usar Redis como um banco de dados primário.
- Recursos Avançados: Suporte a Pub/Sub (Publish/Subscribe) para comunicação em tempo real, transações atômicas, scripts Lua para execução de comandos complexos no servidor, e módulos extensíveis.
- Alta Disponibilidade e Escalabilidade: Oferece soluções robustas como Redis Sentinel para monitoramento e failover automático, e Redis Cluster para sharding automático de dados e escalabilidade horizontal.
- Performance: Geralmente opera com latência de sub-milissegundos. Em benchmarks típicos, pode atingir centenas de milhares de operações por segundo (OPS) em uma única instância, dependendo da máquina e da complexidade das operações.
Memcached
Memcached é um sistema de cache de objetos de memória distribuída de propósito geral. Ele é otimizado para simplicidade e velocidade, sendo focado exclusivamente em armazenar pares chave-valor.
- Simplicidade: Memcached é um sistema de cache puro e simples. Sua API é mais básica, focada em
SET,GETeDELETE. - Multithreading: Ao contrário do Redis (que é single-threaded para processar comandos, mas usa threads para I/O), Memcached é multithreaded, o que pode ser vantajoso em servidores com muitos núcleos de CPU para operações de leitura/escrita.
- Eficiência de Memória: Memcached é conhecido por sua eficiência no uso de memória para armazenar grandes volumes de dados simples. Ele usa um algoritmo de alocação de memória slab para reduzir a fragmentação.
- Sem Persistência: Memcached não oferece persistência de dados. Todos os dados são armazenados puramente em memória RAM e são perdidos em caso de reinício do servidor ou falha. Isso o torna ideal para cache onde a perda de dados é aceitável e a fonte original pode reconstruir o cache.
PONTO-CHAVE
Redis é uma solução mais rica em funcionalidades e estruturas de dados, com persistência e alta disponibilidade, enquanto Memcached é mais simples, focado em cache puro, e otimizado para eficiência de memória e multithreading.
Comparativo: Redis vs. Memcached
A tabela a seguir resume as principais diferenças para ajudar na escolha:
| Característica | Redis | Memcached |
|---|---|---|
| Estruturas de Dados | Strings, Hashes, Lists, Sets, Sorted Sets, Bitmaps, etc. | Apenas Strings (pares chave-valor simples) |
| Persistência | Sim (RDB e AOF) | Não |
| Atomicidade | Transações e scripts Lua para operações atômicas | Operações básicas são atômicas |
| Multithreading | Single-threaded para processamento de comandos (I/O pode ser multi-threaded em versões recentes) | Multithreaded |
| Replicação/Cluster | Sim (Master-Slave, Sentinel, Cluster) | Não nativamente (implementado via clientes) |
| Uso de Memória | Mais alto devido a estruturas de dados e overhead | Mais eficiente para dados simples |
| Casos de Uso Típicos | Cache, banco de dados primário, filas, Pub/Sub, placares | Cache de objetos simples, redução de carga de DB |
PROBLEMAS E SOLUÇÕES
Desafios Comuns e Soluções na Implementação de Cache
Embora o cache ofereça benefícios enormes, sua implementação não é trivial e pode introduzir novos desafios. É crucial estar ciente desses problemas e ter estratégias para mitigá-los.
PROBLEMA 01
Inconsistência de Dados (Stale Data)
O problema mais comum é o “stale data”, onde o cache contém uma versão antiga dos dados enquanto o banco de dados já foi atualizado. Isso pode levar a usuários vendo informações desatualizadas.
SOLUÇÃO — Estratégias de Invalidação e TTL
A solução primária é implementar uma estratégia robusta de invalidação de cache. Isso pode ser feito de várias maneiras:
- Time-to-Live (TTL): Definir um tempo de expiração para cada item no cache. Após esse período, o item é automaticamente removido. Ideal para dados que podem ser ligeiramente desatualizados. Ex:
SETEX mykey 3600 "myvalue"(Redis, expira em 1 hora). - Invalidação Baseada em Eventos: Quando os dados são atualizados no banco de dados, o aplicativo explicitamente remove o item correspondente do cache. Isso garante consistência imediata. Requer um mecanismo para propagar o evento de atualização (ex: Pub/Sub do Redis, filas de mensagens). Ex:
DEL mykey(Redis). - Cache-busting: Adicionar um identificador de versão ao nome da chave do cache ou ao URL do recurso, forçando os clientes a buscarem a nova versão após uma atualização.
EXPLICAÇÃO DO CÓDIGO
Exemplo de como definir um item no Redis com TTL de 60 segundos e como invalidá-lo manualmente.
// Definindo um item com TTL de 60 segundos
redisClient.set('user:123', JSON.stringify({ name: 'João Silva', email: '[email protected]' }), 'EX', 60);
// Em caso de atualização do usuário no DB, invalidar o cache
function updateUser(userId, newData) {
// ... lógica para atualizar o DB ...
redisClient.del(`user:${userId}`); // Invalida o cache
}PROBLEMA 02
Cache Stampede (Thundering Herd)
Ocorre quando um item popular no cache expira e, simultaneamente, um grande número de requisições tenta acessá-lo. Todas as requisições resultam em um “cache miss”, sobrecarregando o banco de dados com múltiplas consultas idênticas.
SOLUÇÃO — Bloqueio de Cache (Mutex) e Refresh-Ahead
Para evitar o cache stampede:
- Bloqueio de Cache (Mutex): Quando o primeiro “cache miss” ocorre, um bloqueio distribuído (usando Redis SETNX ou Redlock) é adquirido. Apenas uma requisição pode prosseguir para o banco de dados para buscar e recarregar o cache. Outras requisições esperam pelo desbloqueio ou retornam um valor padrão temporário.
- Refresh-Ahead: Como discutido anteriormente, o cache é atualizado proativamente antes da expiração, garantindo que nunca haja um período sem dados no cache.
- TTL Jitter: Adicionar uma pequena variação aleatória ao TTL de itens de cache para evitar que todos expirem exatamente ao mesmo tempo.
EXPLICAÇÃO DO CÓDIGO
Exemplo simplificado de bloqueio de cache usando Redis para evitar múltiplas chamadas ao DB quando o cache expira.
async function getProductData(productId) {
const cacheKey = `product:${productId}`;
let data = await redisClient.get(cacheKey);
if (data) {
return JSON.parse(data);
}
// Cache miss - tentar adquirir um lock
const lockKey = `lock:${cacheKey}`;
const locked = await redisClient.set(lockKey, 'true', 'PX', 10000, 'NX'); // Lock por 10s
if (locked) {
try {
// Apenas uma requisição entra aqui
const dbData = await fetchFromDatabase(productId);
await redisClient.set(cacheKey, JSON.stringify(dbData), 'EX', 3600); // Cache por 1h
return dbData;
} finally {
await redisClient.del(lockKey); // Liberar o lock
}
} else {
// Outras requisições esperam ou retornam um valor temporário
await new Promise(resolve => setTimeout(resolve, 100)); // Esperar um pouco
return getProductData(productId); // Tentar novamente
}
}PROBLEMA 03
Gerenciamento de Memória e Custos
A memória é um recurso finito e caro. Um cache mal gerenciado pode consumir memória excessiva, elevando custos e potencialmente degradando o desempenho do próprio servidor de cache.
SOLUÇÃO — Políticas de Evicção e Otimização de Chaves
Para um gerenciamento eficiente de memória:
- Políticas de Evicção: Configure o cache para remover itens automaticamente quando a memória atinge um limite. As políticas comuns incluem
LRU (Least Recently Used),LFU (Least Frequently Used)eRandom. Redis oferece configurações comomaxmemory-policy. - TTL Apropriado: Definir TTLs razoáveis para cada tipo de dado, evitando que itens desnecessários ocupem memória por muito tempo.
- Otimização de Chaves e Valores: Usar chaves curtas e compactar valores (ex: JSON compactado, MessagePack) para economizar espaço. Evitar armazenar dados redundantes.
- Monitoramento: Monitorar o uso de memória do cache para identificar padrões e ajustar as políticas conforme necessário.
PONTO-CHAVE
A invalidação de cache com TTL e eventos, o bloqueio de cache para evitar “stampede”, e políticas de evicção de memória são cruciais para um cache eficiente e robusto.

O diagrama acima ilustra as várias abordagens para invalidação de cache, mostrando como cada método ajuda a manter a consistência dos dados e a otimizar o uso da memória.
APLICAÇÃO PRÁTICA
Guia Prático: Implementando Cache-Aside com Redis
Vamos ver um exemplo prático de como implementar a estratégia Cache-Aside usando Redis em uma API Node.js/Express. O conceito é facilmente adaptável a outras linguagens e frameworks.
1. Configurando o Cliente Redis
Primeiro, certifique-se de ter um servidor Redis em execução (localmente ou na nuvem). Em seguida, instale a biblioteca cliente Redis para sua linguagem. Para Node.js, usaremos ioredis.
EXPLICAÇÃO DO CÓDIGO
Instalando a dependência e configurando o cliente Redis em um arquivo redisClient.js.
// Instalação do ioredis
// npm install ioredis
// redisClient.js
const Redis = require('ioredis');
const redisClient = new Redis({
port: 6379, // Porta padrão do Redis
host: '127.0.0.1', // Host padrão do Redis
password: process.env.REDIS_PASSWORD || undefined, // Se seu Redis tiver senha
connectTimeout: 10000 // Tempo limite de conexão
});
redisClient.on('connect', () => console.log('Conectado ao Redis!'));
redisClient.on('error', (err) => console.error('Erro de conexão com Redis:', err));
module.exports = redisClient;2. Implementando um Endpoint com Cache-Aside
Agora, vamos criar um endpoint Express que busca dados de produtos, aplicando a lógica de Cache-Aside.
EXPLICAÇÃO DO CÓDIGO
Este código mostra um endpoint /products/:id que tenta buscar o produto no Redis primeiro. Se não encontrar, busca no “banco de dados” (simulado aqui) e armazena no cache com um TTL de 3600 segundos (1 hora).
// server.js
const express = require('express');
const redisClient = require('./redisClient'); // Importa o cliente Redis
const app = express();
const PORT = process.env.PORT || 3000;
// Simulação de banco de dados
const productsDB = {
'1': { id: '1', name: 'Laptop Pro', price: 1500, stock: 100 },
'2': { id: '2', name: 'Smartphone Ultra', price: 900, stock: 250 },
'3': { id: '3', name: 'Monitor Gamer', price: 400, stock: 75 }
};
// Função para simular busca no DB
async function fetchProductFromDatabase(productId) {
console.log(`Buscando produto ${productId} no banco de dados...`);
return new Promise(resolve => setTimeout(() => {
resolve(productsDB[productId]);
}, 300)); // Simula latência de 300ms do DB
}
// Endpoint para obter um produto
app.get('/products/:id', async (req, res) => {
const productId = req.params.id;
const cacheKey = `product:${productId}`;
try {
// 1. Tentar buscar no cache
const cachedProduct = await redisClient.get(cacheKey);
if (cachedProduct) {
console.log(`Produto ${productId} encontrado no cache.`);
return res.json(JSON.parse(cachedProduct));
}
// 2. Cache miss: buscar no DB
const product = await fetchProductFromDatabase(productId);
if (!product) {
return res.status(404).json({ message: 'Produto não encontrado.' });
}
// 3. Armazenar no cache com TTL (1 hora)
await redisClient.set(cacheKey, JSON.stringify(product), 'EX', 3600);
console.log(`Produto ${productId} armazenado no cache.`);
res.json(product);
} catch (error) {
console.error('Erro ao buscar produto:', error);
res.status(500).json({ message: 'Erro interno do servidor.' });
}
});
// Endpoint para atualizar um produto (e invalidar cache)
app.put('/products/:id', express.json(), async (req, res) => {
const productId = req.params.id;
const newData = req.body;
try {
// 1. Atualizar no DB (simulado)
if (!productsDB[productId]) {
return res.status(404).json({ message: 'Produto não encontrado para atualização.' });
}
productsDB[productId] = { ...productsDB[productId], ...newData };
console.log(`Produto ${productId} atualizado no banco de dados.`);
// 2. Invalidar o cache
await redisClient.del(`product:${productId}`);
console.log(`Cache para produto ${productId} invalidado.`);
res.json(productsDB[productId]);
} catch (error) {
console.error('Erro ao atualizar produto:', error);
res.status(500).json({ message: 'Erro interno do servidor.' });
}
});
app.listen(PORT, () => {
console.log(`Servidor rodando na porta ${PORT}`);
});PONTO-CHAVE
A implementação de Cache-Aside envolve sempre verificar o cache antes do DB, preencher o cache em caso de “miss”, e invalidar o cache após qualquer operação de escrita no DB para manter a consistência.
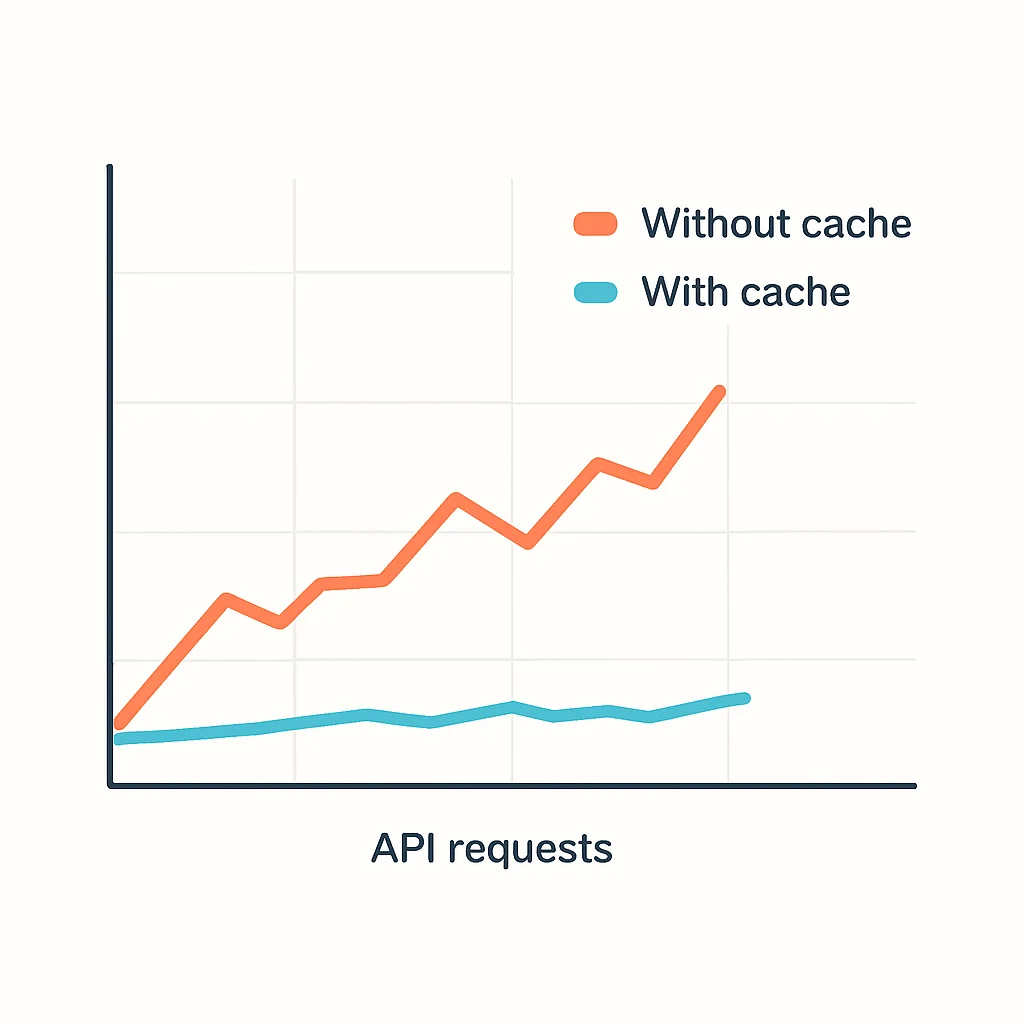
O gráfico acima demonstra claramente o impacto do cache na latência. As requisições que acessam o cache são significativamente mais rápidas, enquanto as que vão diretamente ao banco de dados apresentam latências mais elevadas. Com uma alta taxa de acertos no cache (cache hit ratio), a latência média da API cai drasticamente.
Perguntas Frequentes sobre Cache em APIs
Q. Qual é a principal diferença entre Redis e Memcached para cache de API?
A principal diferença reside na complexidade e nos recursos. Redis é mais versátil, suportando diversas estruturas de dados, persistência e alta disponibilidade, sendo ideal para casos de uso mais complexos. Memcached é mais simples, focado em cache puro de pares chave-valor e otimizado para eficiência de memória, sem persistência.
Q. Como posso garantir que os dados no meu cache não fiquem desatualizados?
Para garantir a consistência, você deve usar uma combinação de Time-to-Live (TTL) para expirar automaticamente itens de cache após um período e invalidação baseada em eventos. Na invalidação por eventos, sempre que os dados originais são modificados no banco de dados, o item correspondente no cache deve ser explicitamente removido ou atualizado.
Q. O que é “Cache Stampede” e como posso evitá-lo?
“Cache Stampede” ocorre quando um item popular do cache expira e muitas requisições tentam buscá-lo do banco de dados simultaneamente, sobrecarregando-o. Isso pode ser evitado com técnicas como bloqueio de cache (usando locks distribuídos para permitir que apenas uma requisição recarregue o cache), Refresh-Ahead (atualização proativa do cache antes da expiração) ou adicionando um “jitter” (variação aleatória) ao TTL.
Q. É sempre uma boa ideia usar cache em todas as APIs?
Não necessariamente. O cache é mais benéfico para dados que são lidos frequentemente e modificados raramente, ou para resultados de operações computacionalmente caras. Para dados que mudam constantemente ou são acessados com pouca frequência, o overhead de gerenciar o cache pode superar os benefícios. É importante analisar os padrões de acesso e a natureza dos dados antes de aplicar o cache.
CONCLUSÃO
Conclusão e Perspectivas Futuras
Em 2026, a otimização de APIs através de estratégias de cache não é apenas uma boa prática, mas um pilar fundamental para a construção de sistemas backend de alta performance, escaláveis e resilientes. Vimos como o cache pode reduzir drasticamente a latência, aumentar o throughput, diminuir a carga em bancos de dados e, em última análise, melhorar a experiência do usuário e reduzir custos operacionais.
A escolha entre ferramentas como Redis e Memcached dependerá dos requisitos específicos do seu projeto. Redis, com suas estruturas de dados ricas e recursos avançados, é uma escolha poderosa para cenários complexos que vão além do cache simples. Memcached, por sua vez, brilha na simplicidade e eficiência para cache de objetos puros. Independentemente da ferramenta, a aplicação de estratégias como Cache-Aside, Write-Through e a gestão cuidadosa da invalidação e da memória são essenciais para o sucesso.
Os desafios como inconsistência de dados, “cache stampede” e gerenciamento de memória podem ser mitigados com as soluções adequadas, como TTLs, invalidação baseada em eventos, bloqueios distribuídos e políticas de evicção. O monitoramento contínuo é vital para ajustar e otimizar a performance do cache ao longo do tempo.
Perspectivas Futuras
Olhando para o futuro, em 2026 e além, as tendências em cache de backend incluem:
- Cache Serverless e Edge Caching: Com a ascensão de arquiteturas serverless e edge computing, veremos mais soluções de cache que operam mais próximas do usuário final, reduzindo ainda mais a latência global.
- Cache Inteligente e Orientado por IA: Algoritmos de aprendizado de máquina podem ser usados para prever quais dados serão acessados e pré-carregar o cache, otimizando as políticas de evicção e invalidação com base em padrões de uso em tempo real.
- Cache Poliglota: A combinação de diferentes tipos de cache (por exemplo, cache de CPU, cache de aplicação local, cache distribuído e CDN) em uma hierarquia otimizada para diferentes níveis de latência e consistência.
Dominar as estratégias de cache é uma habilidade indispensável para qualquer desenvolvedor backend que busca construir sistemas robustos e de alto desempenho no ambiente desafiador de 2026. Ao aplicar os conhecimentos e as ferramentas discutidos aqui, você estará bem equipado para otimizar suas APIs e oferecer uma experiência superior aos seus usuários.
PONTO-CHAVE
A otimização de APIs com cache é um pilar de sistemas modernos, exigindo a escolha certa de ferramentas (Redis/Memcached), estratégias de invalidação, e atenção a tendências como edge caching e IA para performance futura.
Obrigado por ler!
Esperamos que este guia detalhado sobre estratégias de cache tenha sido útil para aprimorar suas APIs em 2026. A performance e a escalabilidade do seu backend são cruciais para o sucesso de qualquer aplicação.
Dúvidas ou sugestões? Deixe um comentário abaixo!