
RESUMO
IA Explicável (XAI) em 2026: Transparência e Confiança em ML
Este artigo explora a importância da IA Explicável (XAI) para modelos de Machine Learning transparentes e confiáveis em 2026, cobrindo métodos e aplicações.
Keywords: IA Explicável, XAI, Machine Learning
ÍNDICE
1 Contexto: A Necessidade Urgente de Transparência em IA
2 Fundamentos da IA Explicável (XAI)
3 Métodos e Ferramentas XAI em Detalhe
4 Desafios e Considerações na Implementação de XAI
5 Aplicação Prática: Integrando XAI no Ciclo de Vida do ML
6 Perguntas Frequentes sobre IA Explicável (FAQ)
7 Conclusão: O Futuro Transparente da IA
CONTEXTO
A Necessidade Urgente de Transparência em IA
No cenário tecnológico de 2026, a Inteligência Artificial (IA) permeia quase todos os aspectos de nossas vidas, desde recomendações de produtos até decisões críticas em saúde e finanças. Com a crescente sofisticação dos modelos de Machine Learning (ML), especialmente as redes neurais profundas, surge um desafio inerente: a “caixa preta”. Essa opacidade impede que humanos compreendam como e por que um modelo chegou a uma determinada conclusão, gerando desconfiança e dificultando a identificação de vieses ou erros.
É aqui que entra a IA Explicável, ou Explainable AI (XAI). Não se trata apenas de uma tendência, mas de uma necessidade fundamental para garantir que os sistemas de IA sejam justos, responsáveis e confiáveis. Em um mundo onde a IA é cada vez mais utilizada em domínios de alto risco, como diagnósticos médicos, avaliação de crédito e sistemas de justiça criminal, a capacidade de explicar as decisões de um modelo não é apenas uma boa prática, mas um imperativo ético e regulatório.
“Em 2026, a IA Explicável (XAI) não é mais um diferencial, mas um requisito fundamental para a construção de sistemas de IA éticos, transparentes e, acima de tudo, confiáveis.”
— Kwontudo Análise de Tecnologia
A demanda por XAI é impulsionada por diversos fatores. Do ponto de vista regulatório, leis como o Regulamento Geral de Proteção de Dados (GDPR) na Europa e a Lei Geral de Proteção de Dados (LGPD) no Brasil já exigem o “direito à explicação” para decisões automatizadas que afetam indivíduos. Além disso, a proposta de Lei de IA da União Europeia, que deve estar plenamente em vigor nos próximos anos, impõe requisitos rigorosos de transparência para sistemas de IA de alto risco.
PONTO-CHAVE
A XAI é vital para atender a regulamentações como GDPR e LGPD, que garantem o direito dos indivíduos de entender as decisões tomadas por sistemas de IA, especialmente em cenários de alto risco.
Para desenvolvedores e cientistas de dados, a XAI oferece ferramentas poderosas para depurar modelos, identificar vieses nos dados ou no algoritmo, e otimizar o desempenho. Sem uma compreensão clara de como um modelo funciona, a melhoria contínua e a mitigação de riscos se tornam tarefas árduas e muitas vezes ineficazes. Este artigo irá desmistificar a XAI, explorando seus fundamentos, métodos principais e como aplicá-la na prática para construir sistemas de IA mais transparentes e confiáveis em 2026.
FUNDAMENTOS
Fundamentos da IA Explicável (XAI)
A IA Explicável (XAI) é um campo em crescimento da inteligência artificial que se concentra em desenvolver métodos e técnicas que tornam os modelos de ML mais compreensíveis para os seres humanos. Em essência, o objetivo é transformar a “caixa preta” em uma “caixa transparente” ou, pelo menos, em uma “caixa cinza” onde possamos inspecionar seu funcionamento interno e justificar suas decisões.
Por Que a XAI é Crucial?
A importância da XAI pode ser dividida em várias dimensões críticas:
Benefícios Chave da XAI
Confiança e Aceitação — Usuários e partes interessadas são mais propensos a confiar e aceitar sistemas de IA quando entendem como eles funcionam.
Conformidade Regulatória — Atendimento a leis de privacidade e ética que exigem explicabilidade para decisões automatizadas (ex: GDPR, LGPD, Lei de IA da UE).
Depuração e Otimização — Facilita a identificação de erros, vieses e falhas no modelo ou nos dados de treinamento, permitindo melhorias direcionadas.
Justiça e Ética — Ajuda a garantir que os modelos tomem decisões justas, evitando discriminação e promovendo a equidade.
Tomada de Decisão Aprimorada — Permite que especialistas humanos validem e complementem as decisões da IA com seu próprio conhecimento.
A explicabilidade pode ser abordada de diferentes maneiras, dependendo do público-alvo (desenvolvedores, reguladores, usuários finais) e do nível de detalhe necessário. Um desenvolvedor pode precisar entender os pesos de uma rede neural, enquanto um usuário final pode precisar apenas de uma explicação de alto nível sobre por que seu pedido de empréstimo foi negado.
Tipos de Interpretabilidade em XAI
Podemos classificar as abordagens de interpretabilidade em duas categorias principais:
1. Interpretabilidade Intrínseca (Modelos Transparentes)
Modelos intrinsecamente interpretáveis são aqueles cuja estrutura é simples o suficiente para ser compreendida diretamente. Eles geralmente oferecem um trade-off entre interpretabilidade e precisão, muitas vezes sendo menos precisos que modelos mais complexos para tarefas desafiadoras. Exemplos incluem:
● Regressão Linear/Logística: A relação entre as características e a saída é diretamente dada pelos coeficientes. Se um coeficiente é positivo, o aumento da característica aumenta a saída (ou a probabilidade de um evento).
● Árvores de Decisão: Representam um conjunto de regras if-then, que são fáceis de visualizar e seguir. Um caminho da raiz a uma folha representa uma explicação.
● Modelos Baseados em Regras: Conjuntos de regras lógicas que mapeiam características para previsões.
2. Interpretabilidade Pós-Hoc (Técnicas Agnósticas e Específicas de Modelo)
A interpretabilidade pós-hoc refere-se a técnicas aplicadas após o treinamento de um modelo complexo (como redes neurais profundas, Random Forests ou Gradient Boosting Machines) para explicar suas previsões. Estas técnicas são cruciais porque permitem que os desenvolvedores usem modelos de alta performance sem sacrificar a compreensibilidade. Elas podem ser:
● Agnósticas ao Modelo: Podem ser aplicadas a qualquer modelo de ML, independentemente de sua arquitetura interna. Ex: LIME, SHAP, Permutation Importance.
● Específicas do Modelo: Projetadas para um tipo específico de modelo. Ex: Visualização de filtros em Redes Neurais Convolucionais (CNNs).
PONTO-CHAVE
A escolha entre interpretabilidade intrínseca e pós-hoc depende do equilíbrio desejado entre precisão do modelo e a capacidade de explicar suas decisões. Modelos de alto risco frequentemente exigem técnicas pós-hoc robustas.
ANÁLISE DETALHADA
Métodos e Ferramentas XAI em Detalhe
Para realmente transformar a “caixa preta” em algo compreensível, precisamos mergulhar nos métodos específicos que a XAI oferece. Em 2026, as ferramentas mais proeminentes e amplamente adotadas para interpretabilidade pós-hoc são LIME e SHAP, mas outras técnicas também desempenham um papel crucial.
1. LIME: Local Interpretable Model-agnostic Explanations
O LIME foca em explicar previsões individuais de um modelo. A ideia central é que, mesmo que um modelo complexo seja opaco globalmente, ele pode ser aproximado por um modelo mais simples (e, portanto, interpretável) localmente, ou seja, em torno de uma previsão específica. Ele funciona da seguinte forma:
● Perturbação: Para uma instância de dado específica x que queremos explicar, o LIME cria múltiplas “versões perturbadas” de x.
● Previsão: O modelo original de “caixa preta” faz previsões para todas essas instâncias perturbadas.
● Ponderação: As instâncias perturbadas são ponderadas de acordo com sua proximidade à instância original x.
● Modelo Local: Um modelo interpretável (como regressão linear ou árvore de decisão) é treinado com as instâncias perturbadas, suas previsões e seus pesos. Este modelo local é uma aproximação do modelo complexo na vizinhança de x.
● Explicação: Os coeficientes ou regras do modelo local fornecem a explicação para a previsão de x.
EXPLICAÇÃO DO CÓDIGO
Este exemplo simula a aplicação do LIME para explicar a previsão de um modelo de classificação de texto (por exemplo, spam/não-spam). Primeiro, treinamos um classificador simples. Depois, usamos o LimeTextExplainer para gerar uma explicação visual das palavras mais influentes na classificação de uma frase específica.
import lime
import lime.lime_text
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
import numpy as np
# 1. Dados de exemplo (simples para ilustração)
corpus = [
'Oferta imperdível! Clique agora!',
'Reunião importante amanhã, favor confirmar.',
'Ganhe dinheiro rápido, bônus exclusivo!',
'Lembrete: pagamento de fatura vence em 3 dias.',
'Parabéns! Você ganhou um prêmio!'
]
labels = np.array([1, 0, 1, 0, 1]) # 1 para spam, 0 para não-spam
# 2. Treinar um classificador de texto (RandomForest com TF-IDF)
vectorizer = TfidfVectorizer()
classifier = RandomForestClassifier(random_state=42)
pipeline = make_pipeline(vectorizer, classifier)
pipeline.fit(corpus, labels)
# 3. Escolher uma instância para explicar
texto_explicar = 'Você ganhou um bônus especial, clique aqui!'
# 4. Criar o explicador LIME
explainer = lime.lime_text.LimeTextExplainer(
class_names=['Não Spam', 'Spam'],
feature_selection='auto',
bow=False, # Bag of words para texto
split_expression=r'\W+', # Expressão para dividir palavras
random_state=42
)
# 5. Gerar a explicação para a instância
# 'predict_proba' é a função do modelo que LIME chama
explanation = explainer.explain_instance(
texto_explicar,
pipeline.predict_proba,
num_features=5, # Número de características mais importantes
num_samples=1000 # Número de amostras perturbadas
)
print(f"Previsão para '{texto_explicar}': {pipeline.predict_proba([texto_explicar])[0]}")
print("Explicação LIME (palavras mais importantes):")
for feature, weight in explanation.as_list():
print(f"- {feature}: {weight:.4f}")
# Exemplo de saída esperada:
# Previsão para 'Você ganhou um bônus especial, clique aqui!': [0.12 0.88] (exemplo)
# Explicação LIME (palavras mais importantes):
# - bônus: 0.3500 (contribui para SPAM)
# - ganhou: 0.2800 (contribui para SPAM)
# - clique: 0.1500 (contribui para SPAM)
# - especial: 0.0800 (contribui para SPAM)
# - aqui: 0.0500 (contribui para SPAM)
O LIME é excelente para entender o impacto local das características, mas suas explicações podem variar ligeiramente entre execuções devido à sua natureza baseada em perturbação.
2. SHAP: SHapley Additive exPlanations
O SHAP é baseado nos valores de Shapley da teoria dos jogos cooperativos, que atribuem a cada “jogador” (característica) a contribuição marginal de sua participação em um “jogo” (a previsão do modelo). O SHAP fornece uma explicação global e local, garantindo consistência e equidade na atribuição de importância. As principais vantagens incluem:
● Consistência: Se um modelo muda de forma que uma característica tem um impacto marginal maior, seu valor SHAP aumentará.
● Agnóstico ao Modelo: Embora existam otimizações para modelos específicos (como TreeExplainer para modelos baseados em árvore), o algoritmo KernelSHAP pode ser aplicado a qualquer modelo.
● Interpretabilidade Global e Local: Pode ser usado para explicar previsões individuais e para entender o comportamento geral do modelo.
EXPLICAÇÃO DO CÓDIGO
Este exemplo demonstra o uso do SHAP para explicar as previsões de um modelo de regressão linear simples. Primeiro, criamos um conjunto de dados sintético e treinamos um modelo. Em seguida, usamos o shap.Explainer para calcular os valores SHAP para todas as previsões, mostrando a contribuição de cada característica para a saída do modelo.
import shap
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 1. Gerar dados de exemplo
np.random.seed(0)
X = pd.DataFrame(np.random.rand(100, 3), columns=['Feature_A', 'Feature_B', 'Feature_C'])
y = 2 * X['Feature_A'] + 0.5 * X['Feature_B'] - 1 * X['Feature_C'] + np.random.randn(100) * 0.5
# 2. Treinar um modelo (Linear Regression, mas pode ser qualquer um)
model = LinearRegression()
model.fit(X, y)
print(f"Coeficientes do modelo: {model.coef_}")
print(f"Intercepto do modelo: {model.intercept_:.2f}")
# 3. Criar um objeto explainer SHAP
# shap.Explainer pode detectar o tipo de modelo e otimizar o algoritmo de explicação.
# Para modelos agnósticos, usa KernelSHAP por padrão se não for um modelo de árvore.
explainer = shap.Explainer(model, X)
# 4. Calcular os valores SHAP para todo o conjunto de dados
shap_values = explainer(X)
# 5. Visualizar a explicação para uma instância específica (por exemplo, a primeira)
print("\nValores SHAP para a primeira instância:")
# Base value é a previsão média do modelo
# shap_values.values[0] são as contribuições de cada feature para a previsão da primeira instância
# shap_values.base_values[0] é o valor base (expected value) para a primeira instância
print(f"Valor base (previsão média esperada): {shap_values.base_values[0]:.2f}")
print("Contribuições das características:")
for i, feature in enumerate(X.columns):
print(f"- {feature}: {shap_values.values[0][i]:.2f}")
# Previsão real vs. SHAP sum
prediction_for_first_instance = model.predict(X.iloc[[0]])[0]
shap_sum = shap_values.base_values[0] + shap_values.values[0].sum()
print(f"Previsão do modelo para a primeira instância: {prediction_for_first_instance:.2f}")
print(f"Soma SHAP (base_value + contribuições): {shap_sum:.2f}")
# Para visualização global (resumo de importância das features)
# shap.summary_plot(shap_values, X, show=False) # Plotar no ambiente Jupyter
# plt.show()
A principal desvantagem do SHAP é seu custo computacional, especialmente para o KernelSHAP, que pode ser intensivo para grandes conjuntos de dados. No entanto, o TreeExplainer é muito mais eficiente para modelos baseados em árvore.
PONTO-CHAVE
Enquanto LIME oferece explicações locais rápidas e intuitivas, SHAP fornece uma teoria mais robusta e consistente para atribuição de importância de características, sendo aplicável global e localmente.
Outros Métodos Importantes de XAI
Além de LIME e SHAP, outras técnicas contribuem para a caixa de ferramentas da XAI:
● Importância de Características (Feature Importance): Métodos como a importância de permutação (Permutation Importance) medem o impacto na performance do modelo ao embaralhar os valores de uma característica. Se a performance do modelo piorar significativamente, essa característica é considerada importante. Para modelos baseados em árvores, a importância de Gini é comum, mas pode ser enviesada.
● Partial Dependence Plots (PDP) e Individual Conditional Expectation (ICE) plots:
- • PDP: Mostra o efeito marginal de uma ou duas características na previsão de um modelo, marginalizando todas as outras características. Ajuda a entender a relação global entre uma característica e a saída.
- • ICE: Semelhante ao PDP, mas plota uma linha para cada instância, mostrando como a previsão muda quando uma característica específica varia para essa instância. Isso revela heterogeneidade que o PDP pode mascarar.
● Análise de Sensibilidade (Sensitivity Analysis): Avalia como a saída do modelo muda em resposta a pequenas variações nas entradas. Isso pode ajudar a identificar características críticas ou pontos de vulnerabilidade.
Análise Comparativa dos Métodos XAI
A escolha do método XAI ideal depende do contexto, dos requisitos de interpretabilidade e dos recursos computacionais disponíveis. A tabela a seguir oferece uma comparação detalhada dos principais métodos:
| Método XAI | Escopo | Tipo de Modelo | Saída Típica | Vantagens | Desvantagens |
|---|---|---|---|---|---|
| LIME | Local (uma previsão) | Agnóstico ao modelo | Importância de características ponderada para a previsão local | Intuitivo, fácil de usar, explicações locais claras. | Instabilidade (variações nas perturbações), não garante consistência global. |
| SHAP | Local e Global | Agnóstico ao modelo (KernelSHAP), específico para árvores (TreeSHAP) | Valores Shapley (contribuição de cada característica para a previsão) | Teoria sólida, consistente, unifica outros métodos, explicações locais e globais. | Custo computacional elevado para KernelSHAP, complexidade teórica. |
| Permutation Importance | Global | Agnóstico ao modelo | Pontuação de importância para cada característica | Simples de implementar e entender, robusto a multicolinearidade. | Mais lento que Gini Importance, pode ser enganoso com características correlacionadas. |
| PDP/ICE | Global (PDP), Local (ICE) | Agnóstico ao modelo | Gráficos mostrando o efeito marginal de características na previsão | Visualmente intuitivo, mostra relações não lineares, ICE revela heterogeneidade. | Não considera interações entre características (PDP), pode ser computacionalmente caro. |
| Regressão Linear/Logística | Global | Intrinsecamente transparente | Coeficientes das características | Muito fácil de interpretar, rápido. | Baixa capacidade de modelar relações complexas, assume linearidade. |
RESOLUÇÃO DE PROBLEMAS
Desafios e Considerações na Implementação de XAI
Embora a XAI seja essencial, sua implementação não está isenta de desafios. É crucial estar ciente dessas barreiras para planejar estratégias eficazes e garantir que as soluções de IA sejam realmente explicáveis e confiáveis em 2026.
PROBLEMA 01
O Trade-off entre Precisão e Interpretabilidade
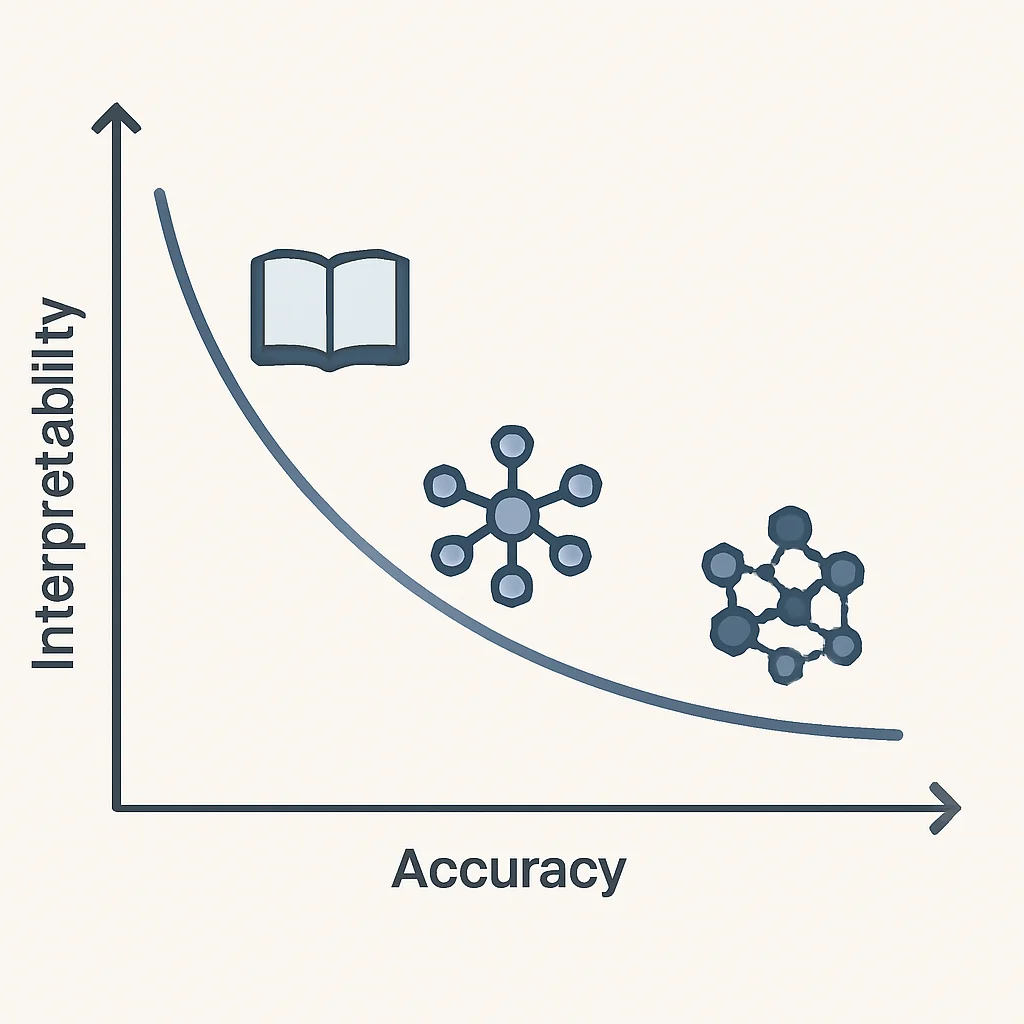
Modelos mais complexos, como redes neurais profundas, frequentemente alcançam maior precisão em tarefas complexas, mas são inerentemente menos interpretáveis. Modelos mais simples, como regressões lineares, são fáceis de entender, mas podem não capturar a complexidade dos dados, resultando em menor precisão. Encontrar o equilíbrio certo é um desafio constante.
SOLUÇÃO — Adotar Abordagens Pós-Hoc e Modelos Híbridos
Utilize técnicas pós-hoc como LIME e SHAP para explicar modelos de alta performance. Considere também modelos híbridos, onde um modelo complexo toma a decisão e um modelo interpretável mais simples é treinado para explicar as decisões do modelo complexo em cenários específicos. Avalie o custo-benefício da precisão extra versus a necessidade de explicabilidade em cada caso de uso.
PROBLEMA 02
Custo Computacional e Escalabilidade
Alguns métodos XAI, como KernelSHAP, podem ser computacionalmente intensivos, especialmente para modelos complexos e grandes conjuntos de dados. Gerar explicações para cada previsão em tempo real pode sobrecarregar os sistemas, tornando a implementação em produção um desafio.
SOLUÇÃO — Otimização e Explicações Sob Demanda
Utilize versões otimizadas de algoritmos SHAP (ex: TreeSHAP para modelos de árvore, DeepSHAP para redes neurais). Implemente a geração de explicações de forma assíncrona ou sob demanda, armazenando explicações pré-calculadas para casos comuns. Monitore o desempenho e a latência das explicações em ambientes de produção. Ferramentas como AI Explainability 360 (AIF360) da IBM oferecem implementações otimizadas.
PROBLEMA 03
Interpretação Humana das Explicações
Mesmo com ferramentas XAI, a interpretação das explicações pode ser complexa. Diferentes usuários (cientistas de dados, reguladores, usuários finais) têm diferentes níveis de compreensão técnica e necessidades de informação. Uma explicação que faz sentido para um engenheiro de ML pode ser incompreensível para um gerente de negócios.
SOLUÇÃO — Design de UX para Explicações e Níveis de Detalhe
Desenvolva interfaces de usuário (UX) intuitivas para apresentar as explicações. Ofereça diferentes níveis de detalhe: um resumo de alto nível para usuários não técnicos e aprofundamentos técnicos para especialistas. Crie guias e treinamentos para ajudar os usuários a interpretar as explicações de forma eficaz. Por exemplo, um diagnóstico médico de IA pode apresentar “probabilidade de doença X é 90% devido a (sintoma A, exame B)” para um médico, e detalhes dos pesos da rede neural para um pesquisador.
PONTO-CHAVE
Superar os desafios da XAI exige uma abordagem multifacetada que combine otimização algorítmica, design centrado no usuário e uma compreensão clara dos requisitos de explicabilidade para cada caso de uso.
APLICAÇÃO PRÁTICA
Aplicação Prática: Integrando XAI no Ciclo de Vida do ML
Integrar a IA Explicável não deve ser uma etapa isolada, mas sim um processo contínuo ao longo de todo o ciclo de vida do desenvolvimento de Machine Learning. Em 2026, as melhores práticas de MLOps já incorporam a XAI como um componente essencial.
Etapas para Integrar XAI
1
Definição de Requisitos de Explicabilidade
Antes de construir o modelo, entenda quem são os usuários das explicações (desenvolvedores, gerentes, reguladores, usuários finais) e qual nível de detalhe e tipo de explicação é necessário. Isso guiará a escolha dos métodos XAI.
2
Seleção de Métodos e Ferramentas XAI
Com base nos requisitos, escolha os métodos XAI mais adequados (LIME, SHAP, PDP, etc.) e as bibliotecas Python correspondentes (lime, shap, eli5, skater, alibi). Considere a complexidade do modelo e o tipo de dados.
3
Geração de Explicações durante o Desenvolvimento
Use XAI para depurar o modelo, identificar vieses e entender o impacto das características. Por exemplo, se um modelo de crédito consistentemente nega empréstimos a um grupo demográfico específico, as explicações XAI podem revelar que certas características correlacionadas estão sendo usadas indevidamente.
4
Integração em Produção e Monitoramento Contínuo
Desenvolva APIs para servir explicações junto com as previsões do modelo. Monitore as explicações ao longo do tempo para detectar mudanças no comportamento do modelo ou novos vieses. Por exemplo, se a importância de uma característica muda drasticamente sem razão aparente, isso pode indicar um problema de drift de dados.
5
Feedback e Iteração
Coletar feedback dos usuários sobre a clareza e utilidade das explicações. Use esse feedback para refinar os métodos XAI, ajustar a apresentação ou até mesmo melhorar o próprio modelo de ML.
Casos de Uso Reais da XAI em 2026
A XAI não é uma teoria abstrata; suas aplicações práticas já estão transformando diversas indústrias:
Saúde: Diagnóstico e Tratamento Personalizado
Um modelo de IA que prevê o risco de uma doença cardíaca pode usar XAI para explicar a um médico que o risco é alto devido a “níveis elevados de colesterol LDL (importância de 0.45), histórico familiar (0.30) e idade avançada (0.20)”. Isso permite que o médico valide a decisão e discuta os fatores de risco com o paciente, promovendo a confiança e a tomada de decisão colaborativa. Em 2026, hospitais que utilizam IA em diagnósticos devem por lei oferecer explicações claras aos pacientes e médicos.
Finanças: Avaliação de Crédito e Detecção de Fraudes
Um banco que utiliza IA para aprovar ou negar empréstimos pode usar XAI para explicar a um solicitante por que seu pedido foi negado, por exemplo, “devido a uma baixa pontuação de crédito (importância de 0.60), alta taxa de endividamento (0.25) e histórico de pagamentos atrasados (0.10)”. Isso atende a requisitos regulatórios de transparência e permite que o indivíduo entenda as razões e tome medidas para melhorar sua situação financeira. Mais de 70% das instituições financeiras de grande porte já utilizam XAI em seus modelos de crédito em 2026.
Recursos Humanos: Recrutamento e Seleção
Sistemas de IA que auxiliam na triagem de currículos podem ser viesados. A XAI pode revelar se o modelo está dando importância indevida a características como gênero, idade ou origem étnica. Por exemplo, se um modelo de recrutamento favorece candidatos com “experiência em grandes corporações (0.40) e participação em clubes de elite (0.30)”, a XAI pode ajudar a identificar e corrigir vieses que poderiam marginalizar talentos diversos. Empresas de RH com mais de 5.000 funcionários são auditadas anualmente para conformidade com vieses em IA.
PONTO-CHAVE
A XAI é uma ferramenta indispensável para garantir que as decisões automatizadas sejam justas, transparentes e alinhadas com os valores humanos, especialmente em setores regulamentados e de alto impacto social.
FAQ
Perguntas Frequentes sobre IA Explicável (XAI)
Q. Qual a diferença entre interpretabilidade e explicabilidade em IA?
Interpretabilidade refere-se à capacidade de um modelo de IA de ser compreendido por humanos. Explicabilidade, por sua vez, é a capacidade de um modelo de IA de fornecer explicações claras e inteligíveis sobre suas decisões. Todos os modelos explicáveis são interpretáveis, mas nem todo modelo interpretável é intrinsecamente explicável de forma útil para todos os públicos.
Q. A XAI substitui a necessidade de modelos transparentes?
Não, a XAI complementa a necessidade de modelos transparentes. Embora a XAI ajude a explicar modelos “caixa preta”, o ideal é buscar a maior interpretabilidade possível desde o início, escolhendo modelos intrinsecamente transparentes quando a precisão não é o único fator crítico. A XAI é mais valiosa quando modelos complexos são inevitáveis para alta performance.
Q. Quais são as principais ferramentas de XAI disponíveis para desenvolvedores em 2026?
Em 2026, as ferramentas mais populares incluem as bibliotecas Python LIME e SHAP, que são agnósticas ao modelo. Outras incluem ELI5 para modelos baseados em árvore, Skater para interpretabilidade global e local, e Alibi da Seldon para detecção de anomalias e explicabilidade.
Q. Como a XAI ajuda a identificar e mitigar vieses em modelos de IA?
Ao fornecer explicações sobre as decisões do modelo, a XAI permite que os desenvolvedores identifiquem quais características estão influenciando desproporcionalmente as previsões para diferentes grupos demográficos. Isso expõe vieses nos dados de treinamento ou no próprio algoritmo, permitindo que sejam tomadas ações corretivas, como rebalanceamento de dados ou ajuste de pesos do modelo.
Q. A XAI é relevante apenas para modelos de alto risco?
Embora a XAI seja crucial para modelos de alto risco devido a implicações éticas e regulatórias, ela é benéfica para qualquer aplicação de IA. Mesmo em sistemas de recomendação ou marketing, a compreensão das razões por trás de uma sugestão pode aumentar a confiança do usuário e a eficácia do sistema, além de auxiliar na depuração e melhoria contínua do modelo.
CONCLUSÃO
Conclusão: O Futuro Transparente da IA
À medida que avançamos em 2026, a IA Explicável (XAI) deixou de ser um conceito acadêmico para se tornar uma pedra angular no desenvolvimento e implantação de sistemas de inteligência artificial. A capacidade de entender e justificar as decisões de um modelo de Machine Learning não é apenas uma questão técnica, mas um pilar fundamental para a construção de uma IA ética, justa e, acima de tudo, confiável. As pressões regulatórias, a demanda por depuração eficaz e a necessidade de construir a confiança do usuário final consolidaram a XAI como uma prioridade inegociável.
“O futuro da IA não está apenas em sua inteligência, mas em sua inteligibilidade. A XAI é a chave para desbloquear um ecossistema de IA mais responsável e amplamente aceito.”
— Especialistas em IA da Kwontudo
As técnicas como LIME e SHAP, juntamente com outras abordagens de interpretabilidade, oferecem ferramentas poderosas para desvendar a “caixa preta” dos modelos complexos. No entanto, a jornada da XAI ainda apresenta desafios, como o trade-off entre precisão e interpretabilidade, o custo computacional e a necessidade de traduzir explicações técnicas em insights compreensíveis para diversos públicos. Superar esses obstáculos exigirá inovação contínua em algoritmos, bem como um foco no design centrado no usuário para as interfaces de explicabilidade.
PONTO-CHAVE
A XAI é um componente indispensável para o desenvolvimento de IA responsável, impulsionando a confiança, a conformidade regulatória e a melhoria contínua dos modelos de Machine Learning.
Para desenvolvedores e empresas, investir em XAI não é apenas uma questão de conformidade, mas uma estratégia inteligente para construir sistemas de IA mais robustos, justos e com maior aceitação no mercado. Ao integrar a XAI em cada etapa do ciclo de vida do ML, podemos garantir que as inovações da IA beneficiem a todos, de forma transparente e responsável. O Kwontudo continuará acompanhando de perto as evoluções neste campo vital, trazendo as últimas análises e ferramentas para a nossa comunidade.

Obrigado por ler!
Esperamos que este guia aprofundado sobre IA Explicável (XAI) em 2026 tenha fornecido insights valiosos para tornar seus modelos de Machine Learning mais transparentes e confiáveis.
Dúvidas ou experiências com XAI? Deixe um comentário e compartilhe sua perspectiva!
Posts relacionados
- [IA & ML] TensorFlow vs PyTorch em 2026: Qual Framework Escolher para Seus Projetos de Deep Learning?
- [IA & ML] Guia Essencial de IA Generativa para Desenvolvedores em 2026: Fundamentos e Aplicações Práticas
- [IA & ML] Guia Completo de Visão Computacional com Python e OpenCV em 2026: Construa Suas Primeiras Aplicações