

RESUMO
SQL vs NoSQL em 2026: Escolha o Banco de Dados Ideal para Seu Projeto
Análise comparativa aprofundada de bancos de dados SQL e NoSQL, com prós, contras e casos de uso, para auxiliar na escolha estratégica do backend em 2026.
Keywords: SQL, NoSQL, Backend
ÍNDICE
1. Contexto: A Escolha Estratégica para o Backend Moderno
2. Análise Detalhada: SQL vs. NoSQL em 2026
3. Desafios e Soluções na Implementação
4. Aplicação Prática: Escolhendo o Banco de Dados Ideal
5. Tendências e Perspectivas para 2026
6. Perguntas Frequentes (FAQ)
1. Contexto: A Escolha Estratégica para o Backend Moderno
No cenário de desenvolvimento de software em 2026, a decisão sobre qual banco de dados utilizar para o backend de uma aplicação é mais crítica do que nunca. A explosão de dados, a demanda por escalabilidade instantânea e a necessidade de processamento em tempo real transformaram essa escolha de uma decisão técnica simples em uma estratégia de negócios fundamental. Um banco de dados mal escolhido pode resultar em gargalos de performance, custos operacionais elevados e, em última instância, no fracasso do projeto. Conforme dados de mercado de 2025, a taxa de crescimento anual composta (CAGR) do mercado global de bancos de dados NoSQL projetada até 2030 é de aproximadamente 20%, enquanto o mercado SQL continua robusto com um CAGR de cerca de 7%, evidenciando a relevância de ambos.
Historicamente, os bancos de dados relacionais (SQL) dominaram o mercado, oferecendo robustez, consistência e um modelo de dados bem definido. No entanto, com o advento das aplicações web em larga escala e a ascensão do Big Data, os bancos de dados não relacionais (NoSQL) surgiram como uma alternativa poderosa, prometendo flexibilidade e escalabilidade horizontal. Em 2026, não se trata mais de uma batalha entre SQL e NoSQL, mas sim de entender qual paradigma, ou combinação deles, se alinha melhor aos requisitos específicos de cada projeto, otimizando recursos e garantindo a resiliência da aplicação.
PONTO-CHAVE
A escolha do banco de dados em 2026 é uma decisão estratégica que impacta diretamente a performance, escalabilidade e custo-benefício de um projeto de backend. Não há uma solução única; a melhor opção depende dos requisitos específicos de dados e operacionais, considerando volumes crescentes e necessidades de processamento em tempo real.
Este relatório de análise se propõe a desmistificar as complexidades de SQL e NoSQL, fornecendo uma visão aprofundada de suas arquiteturas, prós, contras e cenários de uso ideais. Nosso objetivo é equipar você, desenvolvedor, arquiteto ou gerente de produto, com o conhecimento necessário para tomar uma decisão informada e estratégica, garantindo que seu projeto Kwontudo em 2026 seja construído sobre uma base de dados sólida e eficiente. Abordaremos desde os fundamentos teóricos até exemplos práticos e as tendências mais recentes, como bancos de dados multimodelo e serverless.
2. Análise Detalhada: SQL vs. NoSQL em 2026
Para entender qual tecnologia se adapta melhor às suas necessidades, é fundamental mergulhar nas características inerentes de cada paradigma. Vamos comparar suas estruturas, princípios e como eles se comportam sob diferentes cargas de trabalho e modelos de dados, considerando o panorama tecnológico atual de 2026.
SQL: A Base Relacional e Sua Robustez
Os bancos de dados SQL, ou relacionais, são a espinha dorsal de inúmeras aplicações críticas há décadas. Eles são baseados no modelo relacional, onde os dados são organizados em tabelas, com linhas e colunas bem definidas. A chave para a sua robustez reside nos princípios ACID (Atomicidade, Consistência, Isolamento e Durabilidade), que garantem a integridade e confiabilidade dos dados, mesmo em cenários de alta concorrência e falhas de sistema. Por exemplo, em uma transação financeira, o ACID garante que a operação seja totalmente concluída ou totalmente desfeita, sem estados intermediários inconsistentes.
PONTO-CHAVE
Bancos de dados SQL garantem a integridade dos dados através das propriedades ACID, ideal para transações complexas e dados altamente estruturados, onde a consistência é o requisito primordial.
Características Essenciais do SQL
Modelo de Dados Estruturado — Dados organizados em tabelas com esquemas fixos e relações bem definidas entre elas, garantindo a integridade referencial.
Linguagem SQL — Linguagem padrão e declarativa para consulta e manipulação de dados, amplamente conhecida e suportada por uma vasta comunidade de desenvolvedores e DBAs.
Transações ACID — Garante que as operações de banco de dados sejam confiáveis, essenciais para sistemas que não podem tolerar perdas ou inconsistências de dados.
Escalabilidade Vertical — Tradicionalmente escalam adicionando mais recursos (CPU, RAM, disco) a um único servidor, o que pode ser eficaz para cargas de trabalho moderadas, mas tem limites físicos e de custo.
Exemplos proeminentes de bancos de dados SQL incluem PostgreSQL (com sua crescente adoção e suporte a JSONB), MySQL (ainda muito popular para web apps), Oracle Database e Microsoft SQL Server. Em 2026, eles continuam sendo a escolha preferencial para sistemas que exigem alta consistência, como sistemas financeiros (bancos, seguros), e-commerce com gestão de estoque e pedidos, sistemas de ERP (Enterprise Resource Planning) e CRM (Customer Relationship Management). Segundo relatórios de 2025, cerca de 70% das aplicações corporativas críticas ainda dependem de bancos de dados relacionais devido à sua confiabilidade comprovada.
Prós
✓ Alta consistência e integridade de dados (ACID) garantem a confiabilidade transacional.
✓ Modelagem de dados clara e bem definida, facilitando a manutenção e a compreensão de relações complexas.
✓ Suporte robusto a junções e consultas complexas entre tabelas, ideal para análises detalhadas.
✓ Comunidade e ferramentas maduras, ampla documentação e suporte técnico, reduzindo a curva de aprendizado.
Contras
✗ Escalabilidade vertical pode ser cara e atingir limites físicos rapidamente em cenários de crescimento exponencial.
✗ Rigidez do esquema dificulta mudanças rápidas em requisitos de dados, exigindo migrações complexas.
✗ Pode ter dificuldade em lidar com grandes volumes de dados não estruturados ou semi-estruturados, que não se encaixam facilmente no modelo tabular.
A performance de um banco SQL para consultas complexas em dados bem estruturados é excepcional. Por exemplo, em um sistema de e-commerce, uma transação que envolve a atualização do estoque, o registro do pedido e a dedução do valor na conta do cliente, todas em uma única operação atômica, é garantida pelo SQL. Isso minimiza o risco de inconsistências, como vender um produto que já está esgotado ou processar pagamentos incorretos. A otimização de consultas e a indexação eficiente são práticas comuns para manter o alto desempenho em bases SQL com milhões de registros.
NoSQL: Flexibilidade e Escalabilidade para o Futuro
Os bancos de dados NoSQL (Not Only SQL) foram criados para superar as limitações de escalabilidade e flexibilidade dos bancos relacionais, especialmente em cenários de Big Data e aplicações distribuídas. Eles abandonam o modelo relacional em favor de diferentes estruturas de dados, como documentos, pares chave-valor, colunas largas e grafos, e geralmente priorizam a escalabilidade horizontal e a disponibilidade em detrimento da consistência estrita (seguindo o teorema CAP). Em 2026, com o aumento exponencial de dados gerados por IoT e mídias sociais, a relevância do NoSQL continua a crescer, com projeções de que o volume de dados não estruturados excederá 80% do total de dados corporativos.
PONTO-CHAVE
Bancos de dados NoSQL oferecem flexibilidade de esquema e escalabilidade horizontal, ideais para Big Data, dados não estruturados e alta disponibilidade, sendo cruciais para aplicações modernas com requisitos dinâmicos.
Características Essenciais do NoSQL
Modelo de Dados Flexível — Sem esquema fixo (schema-less) ou com esquema dinâmico, adaptando-se a dados não estruturados e semi-estruturados sem a necessidade de migrações complexas.
Escalabilidade Horizontal — Facilmente distribuídos em múltiplos servidores (clusters), permitindo alta disponibilidade e capacidade de lidar com terabytes ou petabytes de dados e milhões de requisições por segundo.
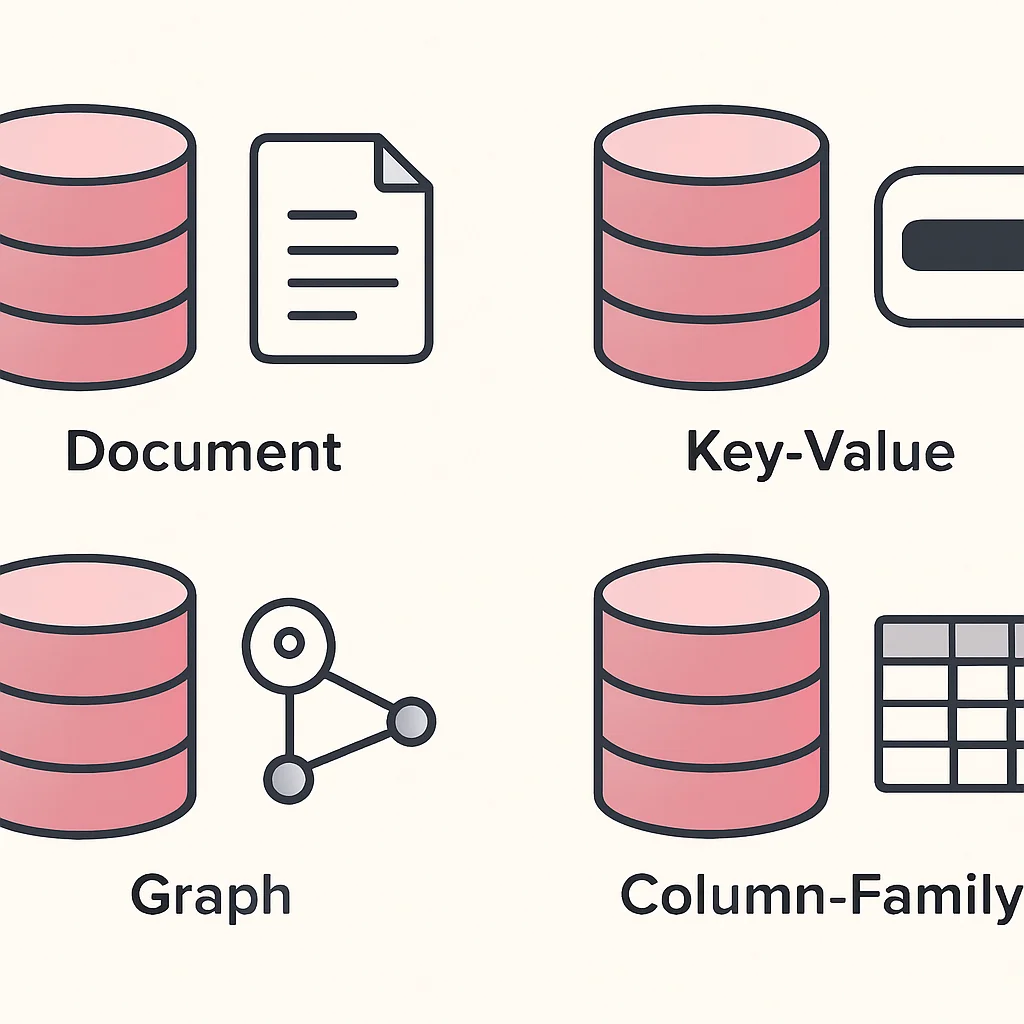
Variedade de Modelos — Quatro tipos principais: Documento, Chave-Valor, Colunar e Grafo, cada um otimizado para casos de uso específicos, permitindo uma escolha mais granular.
Consistência Eventual — Dados podem não estar imediatamente consistentes em todas as réplicas em um sistema distribuído, mas eventualmente se tornam, o que é aceitável para muitas aplicações web.
Os principais tipos de bancos de dados NoSQL e seus exemplos em 2026 incluem:
• Documento: MongoDB, Couchbase. Armazenam dados em documentos flexíveis (JSON, BSON), ideais para CMS, catálogos de produtos e perfis de usuário. Em 2025, MongoDB detinha a maior fatia de mercado entre os bancos NoSQL, com mais de 30%.
• Chave-Valor: Redis, Amazon DynamoDB. Simples e extremamente rápidos para armazenamento e recuperação de dados por chave, ótimos para cache, sessões de usuário e tabelas de classificação. Redis é consistentemente classificado como um dos bancos de dados mais amados pelos desenvolvedores.
• Colunar (Wide-Column): Apache Cassandra, HBase. Otimizados para grandes volumes de dados distribuídos em muitas máquinas, com alta disponibilidade e gravação rápida, usados em IoT (Internet das Coisas) e análise de séries temporais. Cassandra é conhecido por sua capacidade de lidar com petabytes de dados com alta performance.
• Grafo: Neo4j, Amazon Neptune. Modelam dados como nós e arestas, perfeitos para redes sociais, sistemas de recomendação e detecção de fraudes, onde as relações entre os dados são tão importantes quanto os próprios dados.
Prós
✓ Alta escalabilidade horizontal, lidando com terabytes/petabytes de dados e milhões de requisições por segundo de forma eficiente.
✓ Flexibilidade de esquema, permitindo evolução rápida do modelo de dados sem interrupções significativas.
✓ Alta performance para leituras/escritas em larga escala e dados distribuídos, ideal para aplicações com alta demanda de I/O.
✓ Ideal para dados não estruturados, semi-estruturados e Big Data, onde o modelo relacional seria excessivamente complexo ou ineficiente.
Contras
✗ Consistência eventual pode ser um desafio para transações que exigem garantias ACID rigorosas.
✗ Consultas complexas que envolvem junções entre diferentes “coleções” ou “tabelas” são mais difíceis ou inexistentes, exigindo design cuidadoso da aplicação.
✗ Maturidade das ferramentas e ecossistema pode ser menor que a do SQL, embora esteja crescendo rapidamente.
Para ilustrar a flexibilidade do NoSQL, considere uma aplicação de rede social. Novos tipos de dados (curtidas, compartilhamentos, comentários, vídeos) podem ser adicionados a um perfil de usuário sem a necessidade de migrações de esquema complexas. Um banco de dados de documentos como o MongoDB permite que cada documento de usuário tenha uma estrutura ligeiramente diferente, adaptando-se às necessidades em constante mudança da plataforma, o que seria um pesadelo em um ambiente SQL tradicional com esquemas rígidos. A capacidade de escalar horizontalmente significa que, à medida que a base de usuários cresce de centenas de milhares para milhões, o banco de dados pode ser expandido adicionando mais servidores, sem a necessidade de hardware caríssimo.
Comparativo Detalhado: SQL e NoSQL Lado a Lado
A tabela abaixo (conceitual, descritiva) sumariza as principais diferenças e características que devem ser consideradas ao escolher entre SQL e NoSQL em 2026, destacando os pontos críticos de decisão.
Comparativo de Características
Modelo de Dados:
SQL: Relacional (tabelas, linhas, colunas). Esquema fixo e pré-definido, com normalização de dados e relações com JOINs. Essencial para garantir a integridade e evitar redundância.
NoSQL: Variado (documento, chave-valor, grafo, colunar). Esquema flexível ou sem esquema, permitindo a evolução rápida dos dados. Relações geralmente por embed de documentos ou referências, otimizando leituras.
Escalabilidade:
SQL: Principalmente vertical (melhor hardware para um único servidor). Escalabilidade horizontal é complexa (sharding manual ou semi-automático), mas possível com soluções avançadas.
NoSQL: Horizontal por design (distribuição automática entre muitos servidores). Altamente escalável para grandes volumes de dados e tráfego, ideal para Big Data e nuvem.
Consistência:
SQL: Forte (ACID). Garante que todas as transações são válidas e completas, essencial para dados financeiros e críticos.
NoSQL: Geralmente eventual (BASE). Mais flexível, prioriza disponibilidade e performance, mas pode haver atraso na propagação de dados, aceitável para muitos casos de uso web.
Consultas:
SQL: Linguagem SQL, poderosa para consultas complexas, junções, agregações e relatórios. Amplamente padronizada.
NoSQL: APIs específicas ou linguagens de consulta próprias (e.g., MongoDB Query Language, CQL para Cassandra). Menos capacidade para junções complexas entre diferentes coleções/tabelas, otimizadas para recuperação rápida de dados específicos.
Casos de Uso:
SQL: Sistemas transacionais, ERP, CRM, finanças, e-commerce (pedidos, estoque), dados estruturados com alta integridade e requisitos de relatórios complexos.
NoSQL: Big Data, IoT, tempo real, personalização (perfis de usuário), redes sociais, análise de logs, dados não estruturados/semi-estruturados e cenários de alta disponibilidade.
A escolha ideal muitas vezes se resume ao equilíbrio entre consistência e disponibilidade/escalabilidade. Um sistema bancário, por exemplo, não pode comprometer a consistência dos dados, tornando o SQL a escolha óbvia. Já uma plataforma de análise de logs de IoT, que gera terabytes de dados por dia e precisa de alta disponibilidade para ingestão contínua, se beneficiaria imensamente de um NoSQL colunar como o Apache Cassandra. Em 2026, a maioria das empresas busca uma combinação que otimize ambos os aspectos para diferentes partes de suas aplicações.
PONTO-CHAVE
Considere a natureza dos seus dados (estruturados vs. flexíveis), os requisitos de consistência (ACID vs. BASE) e a necessidade de escalabilidade (vertical vs. horizontal) ao comparar SQL e NoSQL. A decisão informada é um alicerce para a performance e a longevidade da sua aplicação.
3. Desafios e Soluções na Implementação
A implementação de qualquer banco de dados, seja SQL ou NoSQL, apresenta desafios únicos que vão além da simples escolha da tecnologia. Entender esses obstáculos e as soluções disponíveis é crucial para o sucesso do projeto e para garantir uma operação fluida a longo prazo. As dores de cabeça mais comuns geralmente giram em torno da evolução do esquema, da gestão da consistência e da complexidade operacional em ambientes distribuídos.
Superando Dilemas Comuns
PROBLEMA 01
Rigidez do Esquema em SQL
Em projetos ágeis, a necessidade de alterar o esquema do banco de dados SQL (adicionar colunas, modificar tipos, criar novas tabelas com relações) pode ser frequente e custosa. Tais mudanças exigem migrações complexas, que podem levar a tempo de inatividade da aplicação e a riscos de perda de dados se não forem gerenciadas adequadamente. Por exemplo, uma alteração em uma tabela grande (com bilhões de linhas) pode levar horas ou até dias.
SOLUÇÃO
Utilize ferramentas de migração de esquema (e.g., Flyway, Liquibase) para gerenciar as alterações de forma versionada e automatizada, garantindo que as mudanças sejam aplicadas de forma consistente em todos os ambientes. Adote uma abordagem de “schema evolution” onde as mudanças são incrementais e retrocompatíveis. Considere o uso de tipos de dados flexíveis como JSONB no PostgreSQL para campos que necessitam de maior flexibilidade dentro de uma estrutura relacional, permitindo armazenar dados semi-estruturados sem alterar o esquema da tabela principal. Implemente blue/green deployments para minimizar o tempo de inatividade durante as migrações.
PROBLEMA 02
Consistência Eventual em NoSQL
Em sistemas NoSQL distribuídos, pode haver um atraso na propagação das atualizações entre os nós do cluster, resultando em dados inconsistentes temporariamente para diferentes usuários. Isso significa que um usuário pode ler uma versão antiga de um dado logo após ele ter sido atualizado, o que é inaceitável para certas operações críticas, como a exibição de um saldo bancário ou a confirmação de um pedido.
SOLUÇÃO
Para operações que exigem alta consistência, implemente estratégias de “leitura forte” (strong consistency) se o banco de dados NoSQL suportar (e.g., MongoDB com write concern “majority” e read concern “majority” ou DynamoDB com consistent reads). Para dados menos críticos, eduque os usuários sobre a consistência eventual ou projete a UI para lidar com isso (e.g., “seu pedido está sendo processado, pode levar alguns segundos para atualizar”). Para cenários híbridos, combine NoSQL para dados flexíveis e de alta disponibilidade (como logs) e SQL para dados transacionais críticos (como pagamentos), garantindo que cada tipo de dado seja persistido na tecnologia mais adequada aos seus requisitos de consistência.
AVISO
Nunca subestime a complexidade da migração de dados e da refatoração de esquemas, especialmente em bancos de dados em produção. Planejamento detalhado, backups completos e testes rigorosos em ambientes de homologação são absolutamente essenciais para evitar perda de dados ou tempo de inatividade prolongado e garantir a integridade do sistema.
PONTO-CHAVE
Antecipe e planeje para desafios como a evolução do esquema e a gestão da consistência desde as fases iniciais do projeto. Soluções incluem ferramentas de migração robustas, estratégias de consistência configuráveis e a adoção de arquiteturas de dados híbridas, que alocam cada tipo de dado ao seu banco ideal.
4. Aplicação Prática: Escolhendo o Banco de Dados Ideal
A decisão entre SQL e NoSQL não deve ser baseada em tendências ou preferências pessoais, mas sim em uma análise cuidadosa dos requisitos do seu projeto, do seu ambiente operacional e das capacidades da sua equipe. Siga esta metodologia passo a passo para tomar uma decisão informada e estratégica, minimizando riscos e maximizando o potencial da sua aplicação.
Metodologia de Seleção
Passo 1
Defina os Requisitos de Dados
Analise a natureza dos seus dados: eles são altamente estruturados e relacionais (e.g., dados financeiros, pedidos de e-commerce, registros de usuários com relações bem definidas)? Ou são flexíveis, semi-estruturados ou não estruturados (e.g., logs de servidores, dados de sensores IoT, perfis de redes sociais com atributos variáveis)? Qual o volume esperado de dados (em GB, TB, PB) e a taxa de crescimento diária/mensal? Estime a quantidade de relações entre entidades e a complexidade das consultas que serão realizadas.
Passo 2
Avalie os Requisitos de Consistência e Disponibilidade
Seu projeto exige consistência transacional forte (ACID) a todo custo (e.g., transações bancárias, controle de estoque crítico)? Ou pode tolerar consistência eventual em troca de alta disponibilidade e escalabilidade (e.g., feeds de notícias, contadores de visualizações, recomendações)? O teorema CAP é um bom guia aqui: você pode ter Consistência ou Disponibilidade em caso de Partição, mas nunca ambos simultaneamente em sistemas distribuídos. Identifique quais dados são críticos e quais podem ter uma consistência mais branda.
Passo 3
Considere Escalabilidade, Custo e Expertise da Equipe
Quanta escalabilidade é necessária para o futuro próximo e a longo prazo, e em que direção (vertical ou horizontal)? Qual é o orçamento disponível para hardware (servidores, armazenamento) e licenciamento de software (se aplicável)? Sua equipe já possui experiência com SQL, com um tipo específico de NoSQL, ou com ambos? A curva de aprendizado de uma nova tecnologia pode impactar o cronograma e a qualidade do projeto. Considere também a maturidade da comunidade, ferramentas de monitoramento e opções de suporte para a tecnologia escolhida.
PONTO-CHAVE
A escolha do banco de dados deve ser um processo sistemático que alinha as características técnicas do banco com os requisitos funcionais e não funcionais do projeto, a capacidade da equipe e as restrições orçamentárias. Um planejamento detalhado aqui evita problemas futuros.
Casos de Uso e Recomendações
Vamos ilustrar com exemplos práticos onde cada tipo de banco de dados brilha, incluindo exemplos de código para demonstrar a interação básica e a lógica de design.
Caso de Uso: Sistema de Gestão Financeira
Um sistema bancário ou de gestão de investimentos requer alta consistência, integridade transacional forte (ACID) e relações complexas entre dados como contas, transações, usuários e extratos. A capacidade de realizar JOINs complexos e a garantia de que as operações financeiras são atômicas e duráveis são cruciais. SQL é a escolha ideal para este cenário.
EXPLICAÇÃO DO CÓDIGO
Este é um exemplo de SQL DDL (Data Definition Language) e DML (Data Manipulation Language) para criar uma tabela de transações e inserir um registro, garantindo a integridade referencial com uma tabela de contas. A transação explícita com START TRANSACTION e COMMIT demonstra a garantia ACID.
-- Criação da tabela de Contas
CREATE TABLE Contas (
conta_id INT PRIMARY KEY AUTO_INCREMENT,
saldo DECIMAL(10, 2) NOT NULL DEFAULT 0.00,
nome_titular VARCHAR(255) NOT NULL,
data_criacao TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Criação da tabela de Transacoes
CREATE TABLE Transacoes (
transacao_id INT PRIMARY KEY AUTO_INCREMENT,
conta_origem_id INT NOT NULL,
conta_destino_id INT NOT NULL,
valor DECIMAL(10, 2) NOT NULL,
data_transacao TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (conta_origem_id) REFERENCES Contas(conta_id),
FOREIGN KEY (conta_destino_id) REFERENCES Contas(conta_id)
);
-- Inserção de dados de exemplo
INSERT INTO Contas (saldo, nome_titular) VALUES (1000.00, 'Alice');
INSERT INTO Contas (saldo, nome_titular) VALUES (500.00, 'Bob');
-- Exemplo de transação (transferência de 100.00 de Alice para Bob)
-- Este bloco garante Atomicidade, Consistência, Isolamento e Durabilidade (ACID)
START TRANSACTION;
-- Atualiza saldo da conta de origem
UPDATE Contas SET saldo = saldo - 100.00 WHERE conta_id = 1;
-- Atualiza saldo da conta de destino
UPDATE Contas SET saldo = saldo + 100.00 WHERE conta_id = 2;
-- Registra a transacao
INSERT INTO Transacoes (conta_origem_id, conta_destino_id, valor) VALUES (1, 2, 100.00);
COMMIT; -- Confirma todas as operações da transacao
-- Consulta para verificar saldos e transacoes
SELECT
C.nome_titular AS Titular,
C.saldo AS SaldoAtual,
T.valor AS ValorTransacao,
T.data_transacao AS DataTransacao
FROM Contas C
LEFT JOIN Transacoes T ON C.conta_id = T.conta_origem_id OR C.conta_id = T.conta_destino_id
WHERE C.nome_titular IN ('Alice', 'Bob')
ORDER BY C.nome_titular, T.data_transacao DESC;
Caso de Uso: Plataforma de Análise de Logs em Tempo Real
Uma plataforma que gerencia um volume massivo de logs não estruturados ou semi-estruturados (e.g., de servidores, aplicações, dispositivos IoT), com necessidade de ingestão rápida, alta disponibilidade e escalabilidade horizontal para picos de dados. A estrutura dos logs pode variar, e a prioridade é a capacidade de ingestão e consulta flexível. NoSQL (documento ou colunar) é a escolha ideal.
EXPLICAÇÃO DO CÓDIGO
Este é um exemplo de como interagir com um banco de dados de documentos (MongoDB) usando JavaScript (Node.js). Ele demonstra a inserção de um novo documento de log com uma estrutura flexível e uma consulta simples para buscar logs de um determinado nível de severidade e de um serviço específico com campos aninhados (metadata).
// Exemplo de código Node.js para interagir com MongoDB
const { MongoClient } = require('mongodb');
// URI de conexão para o servidor MongoDB (local ou em nuvem)
const uri = "mongodb://localhost:27017/?maxPoolSize=20&wTimeoutMS=2500&connectTimeoutMS=10000&socketTimeoutMS=10000"; // Exemplo com opções de conexão
const client = new MongoClient(uri);
async function run() {
try {
// Conecta ao cliente MongoDB
await client.connect();
console.log("Conectado ao MongoDB!");
// Seleciona o banco de dados e a coleção
const database = client.db('log_analytics_db');
const logs = database.collection('server_logs');
// Inserir um novo documento de log com estrutura flexível
const newLog = {
timestamp: new Date(),
level: 'ERROR',
message: 'Falha de autenticação no módulo de usuários.',
service: 'auth-service',
user_id: 'user_xyz',
metadata: { // Objeto aninhado para metadata
ip_address: '192.168.1.10',
browser: 'Chrome',
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/123.0.0.0 Safari/537.36'
},
tags: ['security', 'login'] // Array de tags
};
const result = await logs.insertOne(newLog);
console.log(`\nNovo log inserido com o _id: ${result.insertedId}`);
// Inserir outro log com estrutura ligeiramente diferente (flexibilidade)
const anotherLog = {
timestamp: new Date(),
level: 'INFO',
message: 'Requisição HTTP GET para /api/status.',
service: 'api-gateway',
request_id: 'req_12345',
duration_ms: 50
};
await logs.insertOne(anotherLog);
console.log(`Outro log inserido.`);
// Consultar logs com nível 'ERROR'
const errorLogs = await logs.find({ level: 'ERROR' }).toArray();
console.log('\nLogs de ERRO encontrados:');
errorLogs.forEach(log => console.log(`- [${log.timestamp.toISOString()}] ${log.message}`));
// Consultar logs de um serviço específico com metadata
const authServiceLogs = await logs.find({
service: 'auth-service',
'metadata.ip_address': '192.168.1.10' // Consulta em campo aninhado
}).toArray();
console.log('\nLogs do auth-service do IP 192.168.1.10:');
authServiceLogs.forEach(log => console.log(`- [${log.timestamp.toISOString()}] ${log.message}`));
// Contar o total de logs
const totalLogs = await logs.countDocuments();
console.log(`\nTotal de logs na coleção: ${totalLogs}`);
} finally {
// Garante que o cliente será fechado após as operações
await client.close();
console.log("Conexão MongoDB fechada.");
}
}
run().catch(console.dir);
PONTO-CHAVE
A escolha do banco de dados deve ser guiada por exemplos de código e casos de uso reais que demonstrem como cada tecnologia se encaixa nos requisitos de modelagem de dados, transações e consultas específicas do seu projeto. A adaptabilidade do modelo de dados é um fator chave.
5. Tendências e Perspectivas para 2026
O cenário de bancos de dados está em constante evolução, impulsionado por novas tecnologias e demandas de mercado. Em 2026, algumas tendências se consolidam, impactando diretamente a forma como escolhemos e utilizamos essas tecnologias em projetos de backend.
O Cenário Híbrido e Poliglota
A tendência mais forte em 2026 é a adoção de arquiteturas de dados poliglotas, onde diferentes tipos de bancos de dados são usados em conjunto para otimizar diferentes partes de uma aplicação. Esta abordagem reconhece que nenhum banco de dados é a solução perfeita para todos os problemas. Por exemplo, um e-commerce pode usar PostgreSQL para dados de pedidos e clientes (exigindo ACID), Redis para cache de produtos populares e sessões de usuário (chave-valor de alta velocidade e baixa latência, com tempo de resposta na ordem de milissegundos) e MongoDB para armazenar avaliações de produtos e comentários (documento flexível e escalável para conteúdo gerado pelo usuário).
Essa abordagem permite aproveitar os pontos fortes de cada tecnologia, mitigando suas fraquezas. Grandes empresas como Netflix e Amazon já utilizam modelos híbridos há anos, gerenciando petabytes de dados, e essa prática se tornou mais acessível para projetos de menor escala graças à maturidade de ferramentas de orquestração (como Kubernetes) e plataformas de nuvem que simplificam a gestão de múltiplos serviços de banco de dados. A complexidade de gerenciar múltiplos bancos é compensada pelos ganhos de performance e escalabilidade.
PONTO-CHAVE
A arquitetura poliglota de persistência é a tendência dominante em 2026, combinando SQL e múltiplos tipos de NoSQL para otimizar a performance, a escalabilidade e a resiliência de diferentes componentes de uma aplicação, alinhando a ferramenta à necessidade específica.
Ferramentas e Inovações
A inovação no espaço de banco de dados não para. Em 2026, observamos a ascensão e consolidação de várias tendências e ferramentas que estão redefinindo o panorama da persistência de dados:
Lista de Verificação de Inovações em BD (2026)
☑ Bancos de Dados Multimodelo: Soluções como o ArangoDB, Couchbase e o próprio PostgreSQL com JSONB/PostGIS que combinam diferentes modelos de dados (documento, grafo, chave-valor, relacional) em um único sistema, simplificando a arquitetura e o gerenciamento para certos casos de uso.
☑ Serverless Databases: Bancos de dados gerenciados em nuvem que escalam automaticamente e cobram apenas pelo uso real, como o Amazon Aurora Serverless, Azure Cosmos DB Serverless e Google Cloud Firestore. Essa abordagem reduz significativamente os custos operacionais e a complexidade de gerenciamento, ideal para cargas de trabalho variáveis.
☑ Vector Databases: A ascensão da Inteligência Artificial e Machine Learning impulsionou o desenvolvimento de bancos de dados especializados (e.g., Pinecone, Weaviate) ou extensões em bancos existentes para armazenar e consultar embeddings vetoriais de alta dimensão. São cruciais para sistemas de recomendação, busca semântica e processamento de linguagem natural, com latências de consulta na ordem de dezenas de milissegundos para bilhões de vetores.
☑ Maior Convergência: Bancos SQL modernos (e.g., PostgreSQL) continuam adicionando funcionalidades NoSQL (JSONB), e bancos NoSQL (e.g., MongoDB) melhoram o suporte a transações ACID, borrando as linhas entre eles e oferecendo mais opções híbridas dentro de uma única plataforma.
Essas inovações oferecem novas ferramentas e abordagens para os desafios de persistência de dados, permitindo que as equipes de desenvolvimento criem sistemas ainda mais eficientes, resilientes e adaptados às demandas de 2026. Manter-se atualizado com essas tendências e experimentar as novas tecnologias é essencial para qualquer profissional de backend que busca construir soluções de ponta.
Perguntas Frequentes (FAQ)
Q. Qual banco de dados devo escolher para um novo projeto em 2026?
A escolha depende dos requisitos específicos do seu projeto. Se a integridade dos dados, transações complexas e um esquema rígido são prioritários, um banco SQL (como PostgreSQL) é recomendado. Para alta escalabilidade, flexibilidade de esquema e grandes volumes de dados não estruturados, um NoSQL (como MongoDB ou Cassandra) seria mais adequado. Muitos projetos modernos optam por uma abordagem híbrida.
Q. É possível usar SQL e NoSQL juntos em uma mesma aplicação?
Sim, essa é uma prática cada vez mais comum e recomendada em 2026, conhecida como arquitetura poliglota de persistência. Você pode usar SQL para dados transacionais críticos e NoSQL para dados flexíveis, de cache, de alta taxa de ingestão ou para fins analíticos, aproveitando o melhor de cada tecnologia para diferentes componentes da sua aplicação.
Q. Quais são os principais desafios ao migrar de SQL para NoSQL ou vice-versa?
A migração de SQL para NoSQL envolve a reestruturação do modelo de dados de relacional para um modelo flexível, o que pode ser complexo devido à desnormalização e à adaptação das consultas. A migração inversa (NoSQL para SQL) exige a definição de um esquema rígido a partir de dados potencialmente inconsistentes. Ambos os processos demandam planejamento cuidadoso, backups extensivos e testes rigorosos para evitar perda de dados e garantir a compatibilidade.
Q. Quais ferramentas de banco de dados são mais relevantes em 2026?
Em 2026, PostgreSQL continua sendo uma escolha robusta e popular para SQL, com recursos avançados. No mundo NoSQL, MongoDB (documento), Redis (chave-valor) e Apache Cassandra (colunar) são amplamente utilizados. Soluções multimodelo como ArangoDB e bancos de dados serverless (e.g., Amazon Aurora Serverless) e vetoriais (e.g., Pinecone) também ganham grande destaque e relevância.
Q. Como a IA impacta a escolha de bancos de dados?
A IA e o Machine Learning impulsionam a demanda por bancos de dados que podem