

RESUMO
Observabilidade e Monitoramento na Nuvem
Guia essencial para otimizar aplicações e infraestrutura na nuvem em 2026 com Prometheus e Grafana.
Keywords: Observabilidade, Prometheus, Grafana
ÍNDICE
1. A Ascensão da Observabilidade e Monitoramento na Nuvem em 2026
2. Observabilidade vs. Monitoramento: Entendendo as Diferenças Cruciais
3. Prometheus: A Coleta de Métricas Robusta
4. Grafana: A Visualização e Análise Dinâmica
5. Implementando Prometheus e Grafana na Nuvem: Um Guia Prático
6. Desafios Comuns e Soluções em Observabilidade na Nuvem
7. O Futuro da Observabilidade: Tendências e Próximos Passos
8. Perguntas Frequentes sobre Observabilidade e Monitoramento
CONTEXTO
A Ascensão da Observabilidade e Monitoramento na Nuvem em 2026
No cenário tecnológico em constante evolução de 2026, a complexidade das arquiteturas de software baseadas em nuvem atingiu níveis sem precedentes. Microsserviços, funções serverless, contêineres e infraestrutura como código são a norma, tornando as aplicações mais escaláveis e resilientes, mas também exponencialmente mais difíceis de diagnosticar e otimizar. É nesse contexto que a observabilidade e monitoramento na nuvem se tornam pilares inegociáveis para qualquer equipe de DevOps ou engenharia de software.
Este guia essencial da Kwontudo explora as estratégias e ferramentas mais eficazes para garantir que suas aplicações e infraestrutura na nuvem operem com máxima eficiência e confiabilidade. Focaremos em duas ferramentas líderes de mercado que se complementam perfeitamente: Prometheus para coleta robusta de métricas e Grafana para visualização e análise dinâmica. Juntos, eles formam uma espinha dorsal poderosa para qualquer estratégia de observabilidade moderna.
PONTO-CHAVE
Em 2026, a observabilidade é mais do que monitoramento; é a capacidade de fazer perguntas arbitrárias sobre o estado interno de um sistema para entender comportamentos complexos e imprevistos, essencial para ambientes de nuvem dinâmicos.
A adoção de plataformas de nuvem como AWS, Azure e Google Cloud Platform trouxe agilidade e escalabilidade, mas também introduziu novas camadas de abstração e interdependência. Sem uma visibilidade clara do que está acontecendo “sob o capô”, as equipes podem gastar horas valiosas tentando identificar a causa raiz de problemas de desempenho, latência ou falhas, impactando diretamente a experiência do usuário e os resultados de negócios. Ferramentas como Prometheus e Grafana oferecem a capacidade de coletar, armazenar e visualizar dados de forma eficiente, transformando dados brutos em insights acionáveis.
ANÁLISE DETALHADA
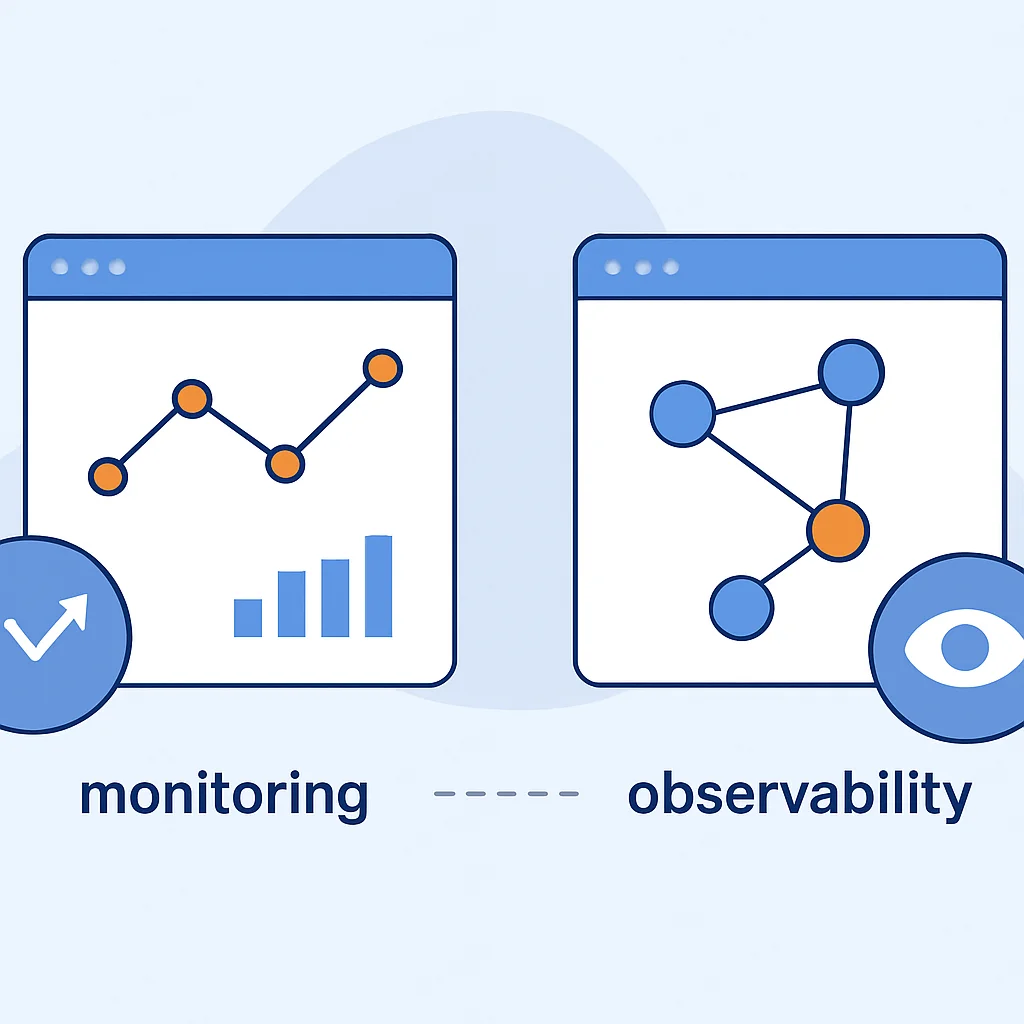
Observabilidade vs. Monitoramento: Entendendo as Diferenças Cruciais
Embora frequentemente usados de forma intercambiável, “monitoramento” e “observabilidade” representam conceitos distintos, porém complementares. Entender essa distinção é fundamental para projetar sistemas resilientes e eficazes em 2026.
O que é Monitoramento?
O monitoramento foca em métricas e logs pré-definidos para verificar a saúde e o desempenho de componentes específicos do sistema. Ele responde a perguntas como: “A CPU está sobrecarregada?” ou “O servidor está online?”. As ferramentas de monitoramento coletam dados conhecidos e esperados, geralmente em intervalos regulares, e disparam alertas quando os limites pré-configurados são excedidos. É uma abordagem mais reativa, baseada em “conhecer o que você não conhece”.
O que é Observabilidade?
A observabilidade, por outro lado, é uma propriedade intrínseca de um sistema que permite inferir seu estado interno a partir de dados externos. Ela se concentra em responder a perguntas como: “Por que a latência aumentou inesperadamente em um microsserviço específico após a última implantação?” ou “Qual a causa raiz de um erro intermitente que afeta apenas 0,1% dos usuários na região X?”. A observabilidade vai além das métricas básicas, incorporando logs detalhados, traces distribuídos e eventos para fornecer um contexto rico e a capacidade de explorar o comportamento do sistema de forma ad hoc.
PONTO-CHAVE
Monitoramento é sobre saber o que está acontecendo (CPU alta). Observabilidade é sobre saber por que está acontecendo (um novo recurso causou um gargalo na CPU).
Pilares da Observabilidade
Métricas — Valores numéricos agregados ao longo do tempo (CPU, memória, latência de requisição).
Logs — Registros de eventos discretos que ocorrem em um sistema (erros, avisos, atividades do usuário).
Traces — Representações visuais de uma única requisição conforme ela se propaga por múltiplos serviços.
Enquanto o monitoramento é essencial para a detecção de problemas conhecidos, a observabilidade é crucial para a investigação de problemas desconhecidos em sistemas complexos e distribuídos. Em ambientes de nuvem, onde a elasticidade e a natureza efêmera dos recursos são a norma, a observabilidade permite que as equipes compreendam o comportamento do sistema em tempo real, mesmo para cenários que não foram antecipados durante o desenvolvimento.
FERRAMENTAS ESSENCIAIS
Prometheus: A Coleta de Métricas Robusta
Prometheus é um sistema de monitoramento e alerta de código aberto, originalmente desenvolvido no SoundCloud. Ele se tornou um padrão de fato para o monitoramento de contêineres e microsserviços, especialmente em ambientes Kubernetes. Sua arquitetura baseada em “pull” (onde o Prometheus coleta métricas dos alvos) o torna altamente flexível e escalável.
Como o Prometheus Funciona
O Prometheus opera coletando métricas de “exporters” (exportadores) que são executados em instâncias de aplicações ou servidores. Esses exporters expõem métricas em um formato HTTP legível pelo Prometheus. O Prometheus então raspa (scrape) esses endpoints em intervalos configuráveis, armazenando os dados em seu próprio banco de dados de séries temporais (TSDB).
PONTO-CHAVE
A linguagem de consulta PromQL do Prometheus é incrivelmente poderosa para análises ad hoc e criação de alertas complexos, permitindo que as equipes identifiquem tendências e anomalias rapidamente.
Principais componentes da arquitetura Prometheus:
Componentes do Prometheus
Prometheus Server — Coleta e armazena métricas. Inclui o servidor HTTP, o armazenamento de séries temporais e o motor de consulta PromQL.
Exporters — Agentes leves que expõem métricas de diversos sistemas (Node Exporter para SO, cAdvisor para contêineres, JMX Exporter para JVM).
Pushgateway — Um gateway opcional para enviar métricas de jobs de curta duração que não podem ser raspados diretamente.
Alertmanager — Gerencia e envia alertas com base nas regras de alerta definidas no Prometheus.
Service Discovery — Integrações com provedores de nuvem (AWS EC2, Kubernetes) para descobrir alvos de raspagem dinamicamente.
Um exemplo de configuração básica para o Prometheus raspando um Node Exporter seria:
EXPLICAÇÃO DO CÓDIGO
Este trecho de código mostra um arquivo de configuração prometheus.yml básico. Ele define o intervalo de raspagem global e um job de raspagem para um node_exporter rodando na porta 9100 do localhost.
global:
scrape_interval: 15s # Raspa os alvos a cada 15 segundos.
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # O próprio Prometheus
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100'] # Um Node Exporter rodando localmenteEssa configuração simples já permite ao Prometheus coletar métricas do seu próprio servidor e de uma instância do Node Exporter, que fornece métricas de sistema operacional (CPU, memória, disco, rede).
VISUALIZAÇÃO DE DADOS
Grafana: A Visualização e Análise Dinâmica
Enquanto o Prometheus é excelente na coleta e armazenamento de métricas, o Grafana brilha na visualização. É uma plataforma de código aberto para análise e monitoramento interativo, permitindo criar dashboards ricos e personalizáveis a partir de diversas fontes de dados, incluindo o Prometheus, InfluxDB, Elasticsearch e muitos outros. Em 2026, o Grafana continua sendo a ferramenta de visualização de escolha para a maioria das equipes de DevOps.
Funcionalidades Chave do Grafana
O Grafana oferece uma interface de usuário intuitiva para construir dashboards que combinam diferentes tipos de visualizações (gráficos de linha, de barra, tabelas, gauges, heatmaps) para apresentar métricas de forma clara e compreensível. Ele suporta:
Recursos do Grafana
Dashboards Dinâmicos — Crie painéis interativos com variáveis de template que permitem filtrar dados por ambiente, serviço, instância, etc.
Múltiplas Fontes de Dados — Conecte-se a uma vasta gama de bancos de dados de séries temporais, bancos de dados relacionais e serviços de log.
Alerting Integrado — Configure alertas diretamente nos dashboards do Grafana, com notificações para Slack, e-mail, PagerDuty, etc.
Plugins Extensíveis — Amplie a funcionalidade com plugins para novas visualizações, fontes de dados e aplicativos.
Annotations — Marque eventos importantes nos gráficos para correlacionar métricas com implantações, incidentes ou outras ocorrências.
A combinação de Prometheus e Grafana oferece uma solução de monitoramento e observabilidade altamente eficaz. O Prometheus coleta os dados brutos e o Grafana os transforma em informações visuais que são fáceis de entender e agir. As consultas PromQL podem ser diretamente usadas no Grafana para criar painéis complexos e detalhados.
PONTO-CHAVE
O Grafana permite a criação de dashboards “single pane of glass”, onde todas as métricas relevantes de diferentes sistemas são visualizadas em um único lugar, facilitando a correlação de eventos e a identificação de problemas.
APLICAÇÃO PRÁTICA
Implementando Prometheus e Grafana na Nuvem: Um Guia Prático
Vamos simular a implantação de Prometheus e Grafana em uma instância de máquina virtual na nuvem (por exemplo, AWS EC2, Google Cloud VM ou Azure VM) para monitorar o próprio sistema operacional da VM usando o Node Exporter.
Passo 1: Preparação da Instância na Nuvem
1
Provisionar uma VM
Crie uma VM (ex: Ubuntu 22.04 LTS) com pelo menos 2 vCPUs e 4GB de RAM. Certifique-se de que as portas 9090 (Prometheus), 9100 (Node Exporter) e 3000 (Grafana) estejam abertas para acesso.
2
Acessar e Atualizar
Conecte-se via SSH e execute sudo apt update && sudo apt upgrade -y.
Passo 2: Instalação do Node Exporter
3
Baixar e Extrair
Baixe a versão mais recente do Node Exporter do GitHub e extraia-o:
EXPLICAÇÃO DO CÓDIGO
Estes comandos baixam o Node Exporter, extraem o arquivo, movem o binário para /usr/local/bin e limpam os arquivos temporários.
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
tar xvfz node_exporter-1.7.0.linux-amd64.tar.gz
sudo mv node_exporter-1.7.0.linux-amd64/node_exporter /usr/local/bin/
rm -rf node_exporter-1.7.0.linux-amd64.tar.gz node_exporter-1.7.0.linux-amd644
Criar Serviço Systemd
Crie um arquivo de serviço para o Node Exporter para que ele inicie automaticamente:
EXPLICAÇÃO DO CÓDIGO
Este comando cria um arquivo node_exporter.service no diretório /etc/systemd/system/, configurando o Node Exporter para ser executado como um serviço.
sudo tee /etc/systemd/system/node_exporter.service > /dev/null <<EOF
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
EOFCrie o usuário node_exporter e inicie o serviço:
EXPLICAÇÃO DO CÓDIGO
Estes comandos criam o usuário do sistema, recarregam as configurações do systemd, habilitam o serviço para iniciar no boot e o iniciam.
sudo useradd -rs /bin/false node_exporter
sudo systemctl daemon-reload
sudo systemctl enable node_exporter
sudo systemctl start node_exporterVerifique se está rodando: curl localhost:9100/metrics. Você deve ver uma longa lista de métricas.
Passo 3: Instalação e Configuração do Prometheus
5
Baixar e Extrair Prometheus
Baixe a versão mais recente do Prometheus e extraia-o:
EXPLICAÇÃO DO CÓDIGO
Estes comandos baixam o Prometheus, extraem o arquivo, criam os diretórios necessários, movem os binários e a interface web para seus locais e limpam os arquivos temporários.
wget https://github.com/prometheus/prometheus/releases/download/v2.51.2/prometheus-2.51.2.linux-amd64.tar.gz
tar xvfz prometheus-2.51.2.linux-amd64.tar.gz
sudo mkdir -p /etc/prometheus /var/lib/prometheus
sudo mv prometheus-2.51.2.linux-amd64/prometheus /usr/local/bin/
sudo mv prometheus-2.51.2.linux-amd64/promtool /usr/local/bin/
sudo mv prometheus-2.51.2.linux-amd64/consoles /etc/prometheus
sudo mv prometheus-2.51.2.linux-amd64/console_libraries /etc/prometheus
rm -rf prometheus-2.51.2.linux-amd64.tar.gz prometheus-2.51.2.linux-amd646
Configurar Prometheus
Crie o arquivo de configuração /etc/prometheus/prometheus.yml:
EXPLICAÇÃO DO CÓDIGO
Este arquivo configura o Prometheus para raspar a si mesmo e o Node Exporter que instalamos anteriormente, ambos na mesma VM.
sudo tee /etc/prometheus/prometheus.yml > /dev/null <<EOF
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
EOFCrie o usuário prometheus e defina as permissões:
EXPLICAÇÃO DO CÓDIGO
Estes comandos criam um usuário e grupo para o Prometheus, garantem que os diretórios de configuração e dados pertencem a este usuário e têm as permissões corretas para segurança.
sudo useradd --no-create-home --shell /bin/false prometheus
sudo chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
sudo chown prometheus:prometheus /usr/local/bin/prometheus
sudo chown prometheus:prometheus /usr/local/bin/promtool7
Criar Serviço Systemd para Prometheus
Crie o arquivo de serviço /etc/systemd/system/prometheus.service:
EXPLICAÇÃO DO CÓDIGO
Este arquivo configura o Prometheus para ser executado como um serviço, especificando os diretórios de configuração e dados.
sudo tee /etc/systemd/system/prometheus.service > /dev/null <<EOF
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus/ \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries
[Install]
WantedBy=multi-user.target
EOFInicie o serviço Prometheus:
EXPLICAÇÃO DO CÓDIGO
Estes comandos recarregam as configurações do systemd, habilitam o serviço Prometheus para iniciar no boot e o iniciam.
sudo systemctl daemon-reload
sudo systemctl enable prometheus
sudo systemctl start prometheusVerifique o Prometheus acessando http://<IP_DA_SUA_VM>:9090 no seu navegador. Você deve ver a interface do Prometheus.
Passo 4: Instalação e Configuração do Grafana
8
Instalar Grafana
Adicione o repositório do Grafana e instale-o:
EXPLICAÇÃO DO CÓDIGO
Estes comandos adicionam a chave GPG do Grafana, configuram o repositório APT e instalam o pacote grafana.
sudo apt-get install -y apt-transport-https software-properties-common wget
sudo wget -q -O /usr/share/keyrings/grafana.key https://apt.grafana.com/gpg.key
echo "deb [signed-by=/usr/share/keyrings/grafana.key] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
sudo apt-get update
sudo apt-get install grafana -y9
Iniciar Grafana
Habilite e inicie o serviço Grafana:
EXPLICAÇÃO DO CÓDIGO
Estes comandos habilitam o serviço Grafana para iniciar no boot e o iniciam imediatamente.
sudo systemctl enable grafana-server
sudo systemctl start grafana-serverAcesse o Grafana em http://<IP_DA_SUA_VM>:3000. O login padrão é admin/admin (você será solicitado a alterar a senha).
10
Adicionar Prometheus como Fonte de Dados no Grafana
No Grafana: Configuration (engrenagem) > Data Sources > Add data source > Prometheus. Configure:
- Name:
PrometheusLocal - URL:
http://localhost:9090 - Clique em
Save & Test. Você deve ver “Data source is working”.
11
Importar um Dashboard de Exemplo
No Grafana: Dashboards > Import. Use o ID 1860 (Node Exporter Full) do site oficial do Grafana Dashboards. Selecione PrometheusLocal como a fonte de dados. Você verá um dashboard completo com métricas do seu servidor.
PONTO-CHAVE
Para ambientes de produção, é altamente recomendável executar Prometheus e Grafana em contêineres Docker ou Kubernetes, usando ferramentas como Helm para gerenciar a implantação e configuração de forma mais robusta e escalável.
RESOLUÇÃO DE PROBLEMAS
Desafios Comuns e Soluções em Observabilidade na Nuvem
Apesar dos benefícios, implementar uma estratégia de observabilidade robusta na nuvem apresenta seus próprios desafios. Em 2026, as equipes precisam estar preparadas para lidar com a escala, a segurança e a complexidade inerente a esses ambientes.
PROBLEMA 01
Gerenciamento de Escala e Armazenamento de Métricas
Com centenas ou milhares de instâncias e microsserviços gerando milhões de métricas, o armazenamento e a consulta de dados podem se tornar um gargalo para o Prometheus, que foi projetado para ser single-node.
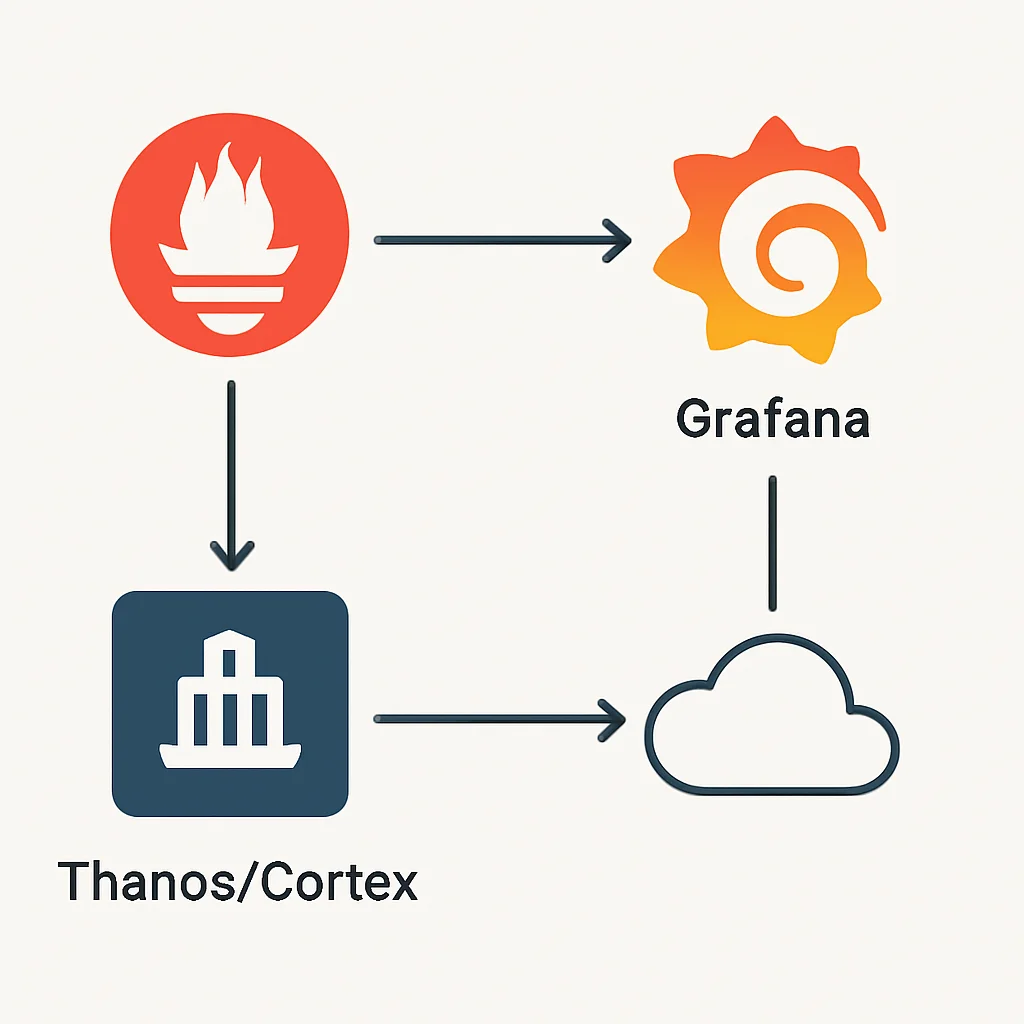
SOLUÇÃO — Escala Horizontal com Soluções de Longa Duração
Utilize soluções de armazenamento de longo prazo compatíveis com Prometheus, como Thanos ou Cortex. Ambos permitem a escala horizontal do Prometheus e o armazenamento de métricas por períodos estendidos em object storage (S3, GCS), além de fornecerem uma API compatível com Prometheus para consulta federada de dados de múltiplos servidores Prometheus.
Para ambientes menores, considere o uso de serviços gerenciados de Prometheus oferecidos pelos provedores de nuvem (ex: Amazon Managed Service for Prometheus).
PROBLEMA 02
Descoberta Dinâmica de Alvos
Em ambientes de nuvem elásticos, as instâncias de aplicações e servidores nascem e morrem constantemente. Configurar manualmente cada alvo de raspagem no Prometheus é inviável.
SOLUÇÃO — Service Discovery Integrado
O Prometheus possui integrações de Service Discovery nativas para diversas plataformas de nuvem e orquestradores. Para Kubernetes, ele pode descobrir automaticamente os serviços e pods. Para AWS EC2, Azure VMs ou GCP Compute Engine, você pode usar o ec2_sd_config, azure_sd_config ou gce_sd_config, respectivamente. Isso automatiza a identificação de novos alvos de monitoramento.
PROBLEMA 03
Correlacionar Métricas, Logs e Traces
Em um incidente, é desafiador correlacionar eventos entre diferentes fontes de dados (métricas do Prometheus, logs do Elasticsearch, traces do Jaeger) para obter uma visão completa da causa raiz.
SOLUÇÃO — Plataformas de Observabilidade Integradas
Embora Prometheus e Grafana sejam excelentes para métricas, a observabilidade completa exige logs e traces. Integre o Grafana com outras ferramentas: Loki para logs e Tempo para traces (ambos da Grafana Labs), ou soluções como Elastic Stack (ELK) e Jaeger. O Grafana pode atuar como um “single pane of glass”, permitindo que você navegue de uma métrica para logs ou traces relacionados, usando links de contexto configurados nos dashboards.
PONTO-CHAVE
A observabilidade na nuvem é um campo em constante evolução. Manter-se atualizado com as novas ferramentas e práticas, como as soluções de armazenamento de longo prazo e service discovery, é crucial para o sucesso.
O FUTURO
O Futuro da Observabilidade: Tendências e Próximos Passos
O campo da observabilidade e monitoramento continua a evoluir rapidamente em 2026. Novas tendências e tecnologias estão moldando a forma como as equipes de DevOps e engenharia abordam a saúde e o desempenho de seus sistemas.
Inteligência Artificial e Machine Learning em Observabilidade (AIOps)
A AIOps está se tornando cada vez mais prevalente. Algoritmos de Machine Learning são usados para:
- Detecção de Anomalias: Identificar padrões incomuns em métricas e logs que podem indicar um problema antes que ele se agrave.
- Correlação de Eventos: Analisar grandes volumes de dados para encontrar relações entre eventos aparentemente não relacionados e identificar a causa raiz mais rapidamente.
- Previsão de Problemas: Prever falhas ou degradações de desempenho com base em tendências históricas.
- Redução de Ruído de Alertas: Agrupar alertas relacionados e priorizá-los, evitando a fadiga de alertas.
Ferramentas como o Prometheus e o Grafana estão começando a integrar recursos de AIOps, seja através de plugins ou de integrações com plataformas especializadas.
OpenTelemetry: Padronização de Dados de Observabilidade
O OpenTelemetry é um conjunto de ferramentas, APIs e SDKs de código aberto que visa padronizar a forma como os dados de telemetria (métricas, logs e traces) são instrumentados, gerados e exportados. Em vez de depender de formatos e agentes proprietários, o OpenTelemetry permite que as aplicações exportem dados em um formato agnóstico de fornecedor. Isso simplifica a troca de ferramentas de observabilidade e reduz o vendor lock-in.
PONTO-CHAVE
Adotar o OpenTelemetry hoje é um investimento no futuro da sua estratégia de observabilidade, garantindo flexibilidade e interoperabilidade à medida que o ecossistema evolui.
Prometheus e Grafana já suportam a ingestão de métricas e traces via OpenTelemetry, tornando-os ainda mais relevantes em um cenário multi-cloud e multi-ferramentas.
Perguntas Frequentes sobre Observabilidade e Monitoramento
Q. Qual a principal diferença entre monitoramento e observabilidade?
R. Monitoramento foca em métricas e alertas pré-definidos para problemas conhecidos (“o que está acontecendo”), enquanto observabilidade permite explorar o estado interno de um sistema para entender problemas desconhecidos (“por que está acontecendo”), usando métricas, logs e traces.
Q. O Prometheus pode coletar logs e traces além de métricas?
R. Não diretamente. O Prometheus é especializado em métricas de séries temporais. Para logs e traces, ele é geralmente combinado com outras ferramentas, como Loki (para logs) e Tempo (para traces), que são da mesma família Grafana Labs e se integram bem.
Q. É possível usar Prometheus e Grafana em ambientes serverless ou de contêineres?
R. Sim, são amplamente utilizados. Para contêineres (Docker, Kubernetes), há exporters específicos (cAdvisor, Kube-state-metrics). Para serverless, o monitoramento pode exigir abordagens diferentes, como o uso do Pushgateway para funções de curta duração ou exporters específicos para as plataformas serverless.
Q. Quais são os desafios de segurança ao implementar observabilidade na nuvem?
R. Os desafios incluem garantir que os dados de métricas e logs não contenham informações sensíveis, proteger os endpoints de raspagem do Prometheus, controlar o acesso aos dashboards do Grafana e gerenciar permissões para acesso a dados de telemetria em ambientes multi-tenant.
Q. Como o OpenTelemetry se encaixa na estratégia de observabilidade com Prometheus e Grafana?
R. O OpenTelemetry atua como a camada de instrumentação e coleta. Ele pode coletar métricas, logs e traces de suas aplicações em um formato unificado. O Prometheus pode raspar as métricas expostas pelo OpenTelemetry Collector, e o Grafana pode visualizar esses dados, além de se conectar a backends de logs (Loki) e traces (Tempo) que também recebem dados do OpenTelemetry.
Obrigado por ler!
Esperamos que este guia essencial tenha fornecido uma visão clara sobre a importância da observabilidade e monitoramento na nuvem em 2026, e como Prometheus e Grafana podem ser ferramentas poderosas em sua estratégia DevOps. Manter seus sistemas visíveis é o primeiro passo para garantir a resiliência e a performance.
Dúvidas ou sugestões? Deixe um comentário abaixo!