

RESUMO
Observabilidade em Sistemas Distribuídos: Guia Completo para 2026
Desvende os segredos para monitorar, analisar e otimizar a performance de sistemas complexos no cenário de 2026.
Keywords: Observabilidade, Sistemas Distribuídos, OpenTelemetry
INTRODUÇÃO
Contexto: A Essência da Observabilidade em 2026
No cenário tecnológico de 2026, os sistemas distribuídos são a espinha dorsal de quase todas as aplicações modernas, desde e-commerce massivo até plataformas de streaming e infraestruturas de IA. A complexidade desses sistemas, com múltiplos microsserviços, funções serverless, contêineres e APIs interconectadas, torna a tarefa de entender o que realmente está acontecendo “dentro” deles um desafio monumental. É aqui que a observabilidade entra em cena, não como um luxo, mas como uma necessidade imperativa.
Observabilidade é a capacidade de inferir o estado interno de um sistema a partir de seus dados de saída. Em termos mais simples, é como ter olhos e ouvidos em cada componente do seu sistema, permitindo que você entenda seu comportamento, identifique gargalos, preveja falhas e resolva problemas rapidamente. Sem uma observabilidade robusta, a depuração em um ambiente distribuído pode se transformar em uma caçada frustrante, impactando diretamente a experiência do usuário e os resultados financeiros. Estudos recentes indicam que empresas com alta maturidade em observabilidade conseguem reduzir o tempo médio para resolução (MTTR) em até 60%, resultando em uma economia anual de milhões de reais em grandes operações.
PONTO-CHAVE
Observabilidade é a capacidade de entender o estado interno de um sistema distribuído analisando métricas, logs e traces. É fundamental para a saúde, performance e resiliência de aplicações modernas em 2026.
Este guia completo do Kwontudo irá desmistificar a observabilidade, explorando seus pilares fundamentais — monitoramento, logs e tracing — e apresentando as ferramentas e as melhores práticas para implementá-la eficazmente em seus sistemas backend em 2026. Prepare-se para transformar a maneira como você interage com a complexidade dos seus sistemas.
CONTEÚDO PRINCIPAL
Os Pilares da Observabilidade: Monitoramento, Logs e Tracing
A observabilidade é construída sobre três pilares interconectados, frequentemente chamados de “Três Pilares da Observabilidade”. Cada um oferece uma perspectiva única sobre o comportamento do sistema e, quando combinados, fornecem uma visão 360 graus que é indispensável para gerenciar sistemas distribuídos em 2026.
1. Monitoramento (Métricas)
O monitoramento é a coleta e análise contínua de métricas numéricas sobre o desempenho e a saúde de um sistema. Métricas são séries temporais de dados, ou seja, valores numéricos medidos em intervalos regulares. Elas são ideais para agregar informações e criar dashboards que mostram tendências ao longo do tempo.
Métricas Essenciais para Monitoramento
Métricas de Desempenho (RED Method) — Taxa de Requisições (Request Rate), Erros (Errors), Duração (Duration/Latency) são cruciais para qualquer serviço.
Métricas de Utilização (USE Method) — Utilização (Utilization), Saturação (Saturation), Erros (Errors) para recursos como CPU, memória, disco e rede.
Métricas de Negócio — KPIs específicos como número de conversões, usuários ativos, valor total de vendas, que ligam a performance técnica ao impacto comercial.
Métricas de Infraestrutura — Uso de CPU, memória, I/O de disco, tráfego de rede para servidores, contêineres e VMs.
PONTO-CHAVE
Métricas são dados numéricos agregados que fornecem uma visão de alto nível sobre a saúde e o desempenho do sistema. São excelentes para identificar tendências, criar alertas proativos e visualizar o estado geral.
Por exemplo, em um microsserviço de processamento de pedidos, métricas como http_requests_total (contador de requisições), http_request_duration_seconds (histograma de latência) e database_connections_open (gauge de conexões abertas) seriam cruciais. Ferramentas como Prometheus e Grafana são líderes nesse espaço em 2026, permitindo a coleta, armazenamento e visualização dessas métricas com grande eficiência.
2. Logs
Logs são registros textuais de eventos que ocorrem em um sistema. Ao contrário das métricas, que são agregadas, os logs fornecem detalhes granulares sobre eventos específicos, como uma transação de usuário, uma falha de autenticação ou uma exceção de código. Eles são inestimáveis para a depuração de problemas específicos e para entender a sequência de eventos que levaram a uma determinada situação.
Em sistemas distribuídos, a prática de logging estruturado tornou-se padrão em 2026. Em vez de texto livre, os logs são gerados em formatos como JSON, que podem ser facilmente indexados e pesquisados por ferramentas de gerenciamento de logs. Incluir identificadores de correlação (como um request_id ou trace_id) em cada entrada de log é vital para conectar eventos através de diferentes serviços.
EXPLICAÇÃO DO CÓDIGO
Este exemplo em Python demonstra como gerar logs estruturados em formato JSON, incluindo informações contextuais como request_id e service_name, que são cruciais para correlação em ambientes distribuídos.
import logging
import json
import uuid
from datetime import datetime
class JsonFormatter(logging.Formatter):
def format(self, record):
log_record = {
"timestamp": datetime.fromtimestamp(record.created).isoformat(),
"level": record.levelname,
"service_name": "order-processor-service",
"message": record.getMessage(),
"request_id": getattr(record, 'request_id', 'N/A'),
"user_id": getattr(record, 'user_id', 'N/A'),
"component": record.name,
"filename": record.filename,
"lineno": record.lineno,
"thread": record.threadName,
"process": record.process,
"extra_data": getattr(record, 'extra_data', {})
}
if record.exc_info:
log_record["exception"] = self.formatException(record.exc_info)
return json.dumps(log_record)
# Configuração do logger
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(JsonFormatter())
logger.addHandler(handler)
# Exemplo de uso
request_id = str(uuid.uuid4())
user_id = "user-123"
logger.info("Processando novo pedido", extra={'request_id': request_id, 'user_id': user_id, 'order_id': 'ORD-456'})
logger.warning("Falha na validação de dados", extra={'request_id': request_id, 'user_id': user_id, 'validation_error': 'invalid_email'})
try:
1 / 0
except ZeroDivisionError as e:
logger.error("Erro inesperado durante o cálculo", exc_info=True, extra={'request_id': request_id})
Ferramentas como o ELK Stack (Elasticsearch, Logstash, Kibana) ou Loki em conjunto com Grafana, são amplamente utilizadas para centralizar, indexar e visualizar logs de múltiplos serviços, permitindo buscas rápidas e análise de padrões.
3. Tracing Distribuído
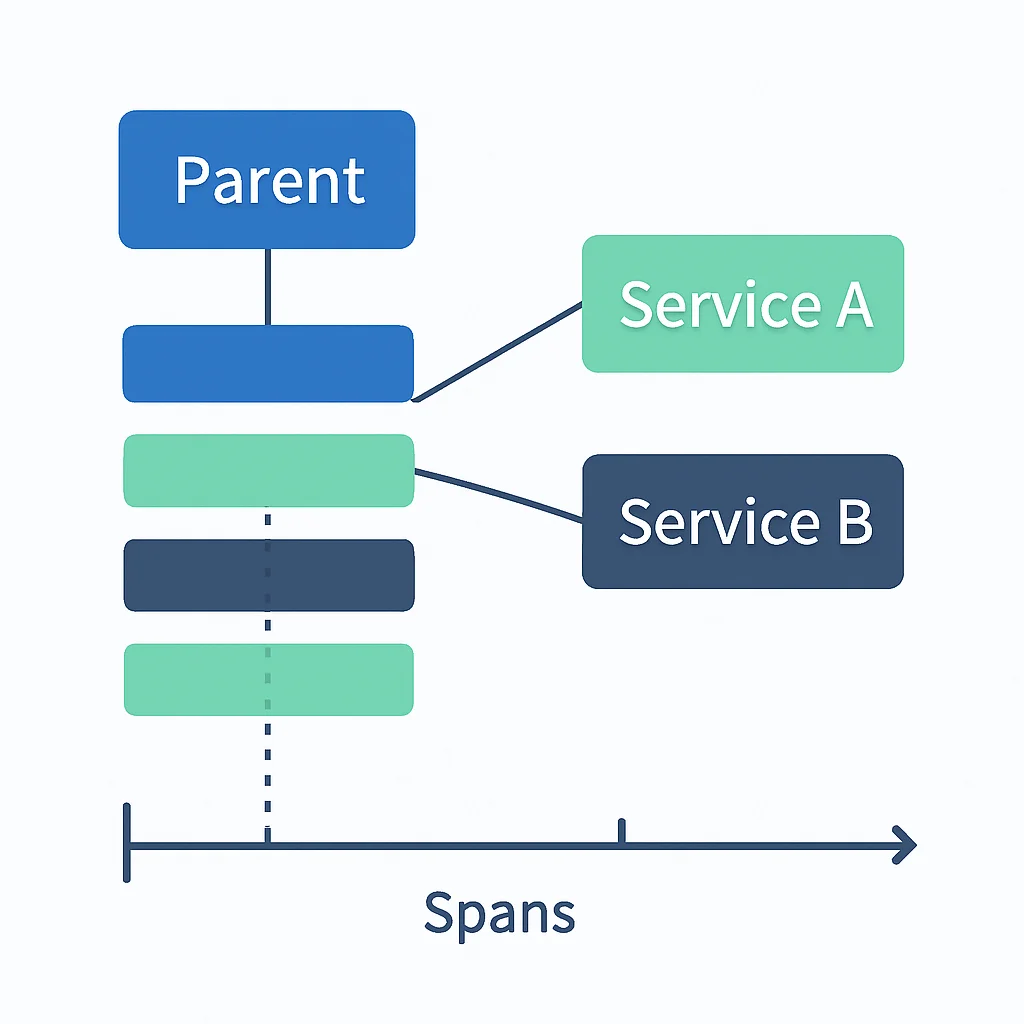
O tracing distribuído é o pilar que permite acompanhar o fluxo de uma única requisição (ou transação) à medida que ela se propaga por todos os serviços em um sistema distribuído. Ele visualiza a jornada completa, desde o ponto de entrada (por exemplo, um gateway de API) até os serviços internos, bancos de dados e APIs externas que são chamados para atender à requisição.
Um “trace” é composto por “spans”, onde cada span representa uma operação individual dentro de um serviço (como uma chamada de função, uma requisição HTTP ou uma consulta a um banco de dados). Os spans são hierárquicos (parent-child relationship) e contêm metadados como nome da operação, tempo de início/fim, atributos (tags) e eventos (logs dentro do span).
O tracing é fundamental para:
✓ Identificar gargalos de performance em cadeias de serviços.
✓ Realizar análise de causa raiz de falhas complexas que envolvem múltiplos componentes.
✓ Entender dependências entre serviços.
✓ Otimizar fluxos de trabalho e arquiteturas de microsserviços.
EXPLICAÇÃO DO CÓDIGO
Este pseudocódigo ilustra como o OpenTelemetry é usado para instrumentar um serviço, criando spans para operações e propagando o contexto de trace entre serviços através de cabeçalhos HTTP. Isso permite que uma requisição seja rastreada do início ao fim em um ambiente distribuído.
// Serviço A: Gateway de API
function handleRequest(request) {
// 1. Inicia um novo trace para a requisição de entrada
const span = tracer.startSpan('http-request-handler', {
attributes: { 'http.method': request.method, 'http.url': request.url }
});
// Define este span como o span pai para as operações subsequentes
const ctx = opentelemetry.context.active().with(opentelemetry.trace.setSpan(span));
// 2. Propaga o contexto do trace para o serviço B (via cabeçalhos HTTP)
const headers = {};
opentelemetry.propagation.inject(ctx, headers);
// 3. Chama o serviço B
const responseB = await fetch('http://service-b/process', { headers });
// 4. Finaliza o span do manipulador de requisição
span.end();
return responseB;
}
// Serviço B: Processador de Negócios
function processData(request) {
// 1. Extrai o contexto do trace dos cabeçalhos HTTP
const ctx = opentelemetry.propagation.extract(opentelemetry.context.active(), request.headers);
// 2. Cria um novo span para a operação atual, com o contexto do trace extraído
const span = tracer.startSpan('process-data-operation', {
attributes: { 'data.size': request.body.length }
}, ctx);
// 3. Simula alguma lógica de negócio
await someDatabaseCall(span); // Cria um span filho para a chamada ao DB
await anotherInternalOperation(span); // Cria outro span filho
// 4. Finaliza o span
span.end();
return { status: 'processed' };
}
// Função auxiliar para chamadas a banco de dados (também instrumentada)
async function someDatabaseCall(parentSpan) {
const dbSpan = tracer.startSpan('database-query', {
attributes: { 'db.type': 'sql', 'db.statement': 'SELECT * FROM users' }
}, opentelemetry.context.active().with(opentelemetry.trace.setSpan(parentSpan)));
// Simula uma consulta ao DB
await new Promise(resolve => setTimeout(resolve, 50));
dbSpan.end();
}
FERRAMENTAS
Ferramentas e Tecnologias Essenciais para 2026
A implementação eficaz da observabilidade requer um ecossistema de ferramentas robusto. Em 2026, a paisagem de ferramentas está mais madura e integrada do que nunca, com padrões abertos ganhando destaque. Vamos explorar as principais tecnologias que dominam o espaço.
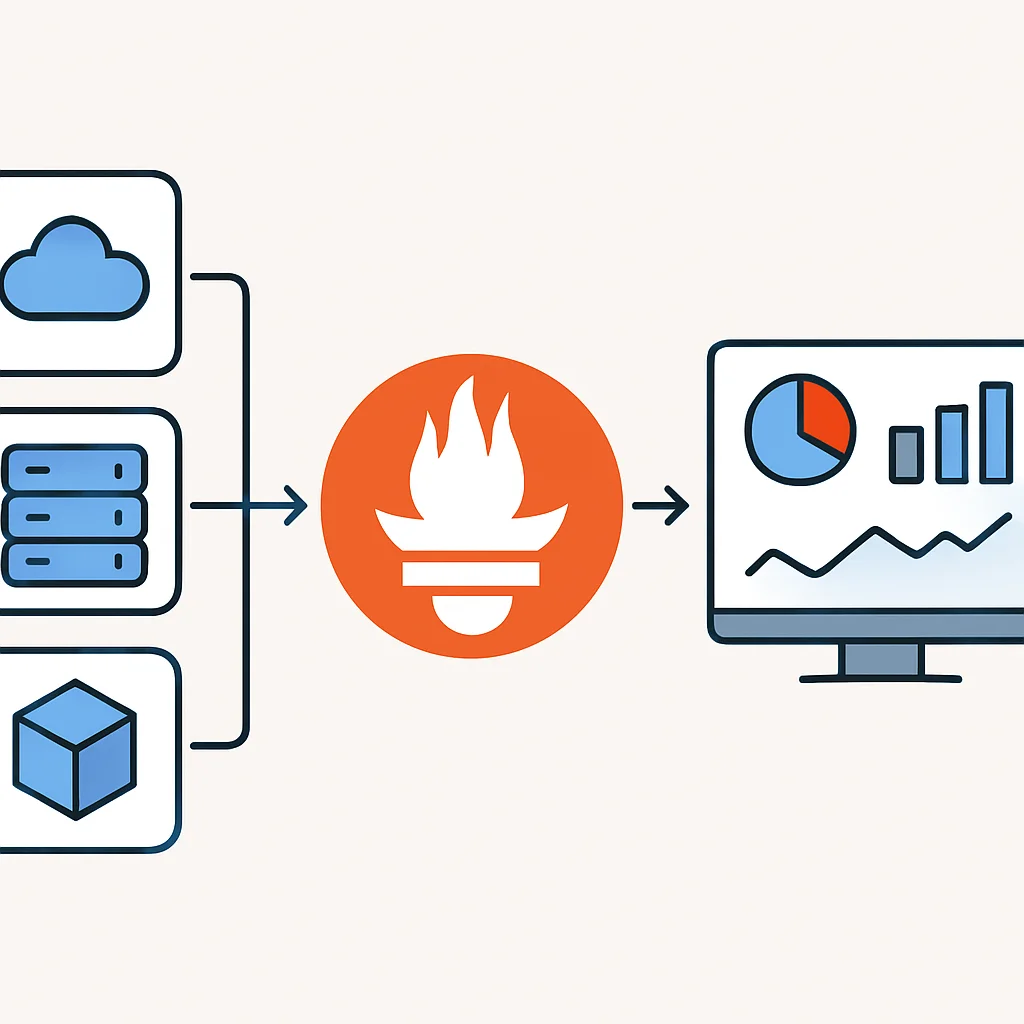
Prometheus e Grafana: A Dupla Dinâmica do Monitoramento
Prometheus é um sistema de monitoramento e alerta de código aberto que coleta métricas de alvos configurados em intervalos definidos, avalia regras de expressão, exibe os resultados e pode disparar alertas se certas condições forem atendidas. Sua arquitetura baseada em “pull” (onde o Prometheus “puxa” as métricas dos serviços) e seu modelo de dados de séries temporais são ideais para a granularidade e escala de sistemas distribuídos. É o padrão de fato para monitoramento de contêineres e Kubernetes.
Grafana é a plataforma de visualização e dashboarding de código aberto mais popular que se integra perfeitamente com o Prometheus (e muitas outras fontes de dados). Com o Grafana, você pode criar dashboards interativos e personalizáveis que exibem as métricas coletadas pelo Prometheus em tempo real, permitindo uma análise rápida e eficaz do desempenho do sistema. A combinação de Prometheus para coleta/armazenamento e Grafana para visualização é uma solução poderosa e amplamente adotada.
PONTO-CHAVE
Prometheus e Grafana formam a base para o monitoramento de métricas em 2026, oferecendo coleta eficiente, armazenamento de séries temporais e visualização rica para identificar tendências e anomalias.
OpenTelemetry: O Padrão Universal para Instrumentação
Em 2026, o OpenTelemetry (OTel) se consolidou como o padrão da indústria para instrumentação de observabilidade. OTel é um conjunto de ferramentas, APIs e SDKs de código aberto que padroniza a forma como métricas, logs e traces são gerados e coletados de suas aplicações. Sua principal vantagem é a neutralidade do fornecedor: você instrumenta seu código uma vez com OTel, e pode exportar os dados para qualquer backend de observabilidade compatível (Prometheus, Jaeger, Zipkin, ou plataformas comerciais como Datadog, New Relic, etc.).
Isso resolve o problema de “vendor lock-in” e simplifica enormemente a gestão da observabilidade em ambientes heterogêneos. Com o OTel, a coleta de dados de observabilidade torna-se uma preocupação arquitetônica central, não uma decisão específica de ferramenta.
Gerenciamento de Logs: ELK Stack vs. Loki
Para logs, as opções mais populares são o ELK Stack e, mais recentemente, o Loki.
Prós do ELK Stack (Elasticsearch, Logstash, Kibana)
✓ Poderoso e maduro: Solução completa para ingestão, armazenamento, busca e visualização de logs, com capacidade de pesquisa full-text.
✓ Análise de dados avançada: Elasticsearch é um motor de busca distribuído que permite consultas complexas e agregações sobre grandes volumes de dados.
✓ Ecossistema rico: Grande comunidade e muitos plugins/integrações.
Contras do ELK Stack
✗ Alto consumo de recursos: Elasticsearch pode ser bastante exigente em termos de CPU, memória e armazenamento, especialmente com grandes volumes de logs.
✗ Complexidade operacional: Gerenciar um cluster Elasticsearch distribuído requer expertise significativa.
✗ Custo: Pode ser caro em ambientes de nuvem devido ao consumo de recursos.
Prós do Loki (Grafana Labs)
✓ Eficiência de recursos: Loki não indexa o conteúdo dos logs, apenas os metadados (rótulos), o que o torna muito mais leve e econômico.
✓ Escalabilidade: Projetado para ser altamente escalável e eficiente, especialmente para logs de contêineres e Kubernetes.
✓ Integração com Grafana: Perfeita integração com Grafana usando LogQL, a linguagem de consulta inspirada no PromQL.
Contras do Loki
✗ Menos flexibilidade de busca: Como não indexa o conteúdo, as buscas são mais lentas se não forem baseadas em rótulos.
✗ Dependência de rótulos: A eficiência depende da boa definição e aplicação de rótulos nos logs.
✗ Menos recursos analíticos: Não possui a mesma capacidade de análise e agregação de dados do Elasticsearch.
A escolha entre ELK e Loki depende das necessidades específicas do seu projeto e do volume de logs. Para sistemas massivos com necessidade de buscas complexas e analíticas sobre o conteúdo dos logs, ELK pode ser a escolha. Para ambientes Kubernetes com foco em eficiência e integração com Prometheus/Grafana, Loki brilha em 2026.
GUIA PRÁTICO
Implementando Observabilidade: Um Guia Prático
Implementar observabilidade não é um evento único, mas um processo contínuo que evolui com o sistema. Siga estes passos para construir uma estratégia robusta:
DESAFIOS & BOAS PRÁTICAS
Desafios e Boas Práticas em Sistemas Distribuídos
Apesar dos enormes benefícios, a implementação da observabilidade em sistemas distribuídos vem com seu próprio conjunto de desafios. Entender e abordar esses pontos é crucial para o sucesso em 2026.
AVISO
Nunca inclua informações de identificação pessoal (PII) ou dados sensíveis em logs, métricas ou traces sem anonimização ou mascaramento rigoroso. Isso é crucial para conformidade com LGPD e GDPR, e para a segurança dos dados de seus usuários.
PONTO-CHAVE
A observabilidade é uma jornada contínua. Comece com o básico (métricas RED/USE), adicione logs estruturados e, em seguida, implemente tracing. Itere e refine suas estratégias com base nas necessidades e nos desafios que surgirem.
Outras boas práticas incluem:
✓ Shift-Left Observability: Integre a instrumentação no início do ciclo de desenvolvimento, não como um pós-pensamento.
✓ Cultura de Observabilidade: Eduque suas equipes sobre a importância da observabilidade e como usar as ferramentas. Torne os dashboards e traces acessíveis a todos.
✓ Dashboards Acionáveis: Crie dashboards que contem uma história, focando em métricas chave que podem levar a ações. Evite “dashboards de parede” com centenas de gráficos irrelevantes.
✓ Testes de Carga e Chaos Engineering: Use a observabilidade para validar o comportamento do sistema sob carga e para entender como ele se comporta em falhas simuladas.

CASOS DE USO
Casos de Uso e Análise Comparativa
A observabilidade é aplicável a uma vasta gama de arquiteturas e cenários. Vamos explorar alguns dos mais relevantes em 2026.
Microsserviços
Em uma arquitetura de microsserviços, a observabilidade é a chave para o sucesso. Com dezenas ou centenas de serviços interagindo, o tracing distribuído é indispensável para visualizar o fluxo de requisições e identificar o serviço exato que está causando um problema de latência ou um erro. Métricas agregadas por serviço e logs centralizados permitem que as equipes de serviço monitorem a saúde de suas próprias aplicações sem afetar outras.
Exemplo: Uma requisição de compra falha. O trace distribuído revela que o serviço de estoque demorou 15 segundos para responder, causando um timeout no serviço de pedidos. Os logs do serviço de estoque mostram que uma consulta de banco de dados específica estava lenta devido a um índice ausente.
Ferramentas: OpenTelemetry para instrumentação, Prometheus/Grafana para métricas, Jaeger para traces, Loki/ELK para logs.
Funções Serverless (FaaS)
Funções serverless (como AWS Lambda, Azure Functions) são efêmeras e escalam automaticamente, tornando o monitoramento tradicional difícil. A observabilidade deve ser intrínseca. Métricas de invocação, duração e erros são essenciais. Logs de cada execução de função são vitais para depuração. O tracing ajuda a conectar eventos entre funções e outros serviços da nuvem.
Exemplo: Uma função Lambda que processa uploads de imagem está gerando muitos erros. As métricas mostram um aumento nos erros e na duração. Os logs da função revelam que o tempo limite (timeout) está sendo atingido devido a um processamento de imagem muito longo para arquivos grandes.
Ferramentas: SDKs de observabilidade nativos da nuvem (CloudWatch, Azure Monitor), OpenTelemetry para instrumentação personalizada, Grafana para visualização consolidada.
Sistemas Legados e Monolíticos
Mesmo sistemas monolíticos podem se beneficiar enormemente da observabilidade. Embora o tracing distribuído seja menos complexo (ou inexistente), métricas detalhadas e logs estruturados podem revelar gargalos internos, uso ineficiente de recursos e pontos de falha que antes eram opacos. A observabilidade pode ser um primeiro passo crucial na modernização de um monólito, identificando áreas para refatoração em microsserviços.
Exemplo: Um monólito tem picos de CPU inexplicáveis. Métricas mostram que um endpoint específico está consumindo muitos recursos em horários de pico. Logs revelam que esse endpoint está fazendo consultas de banco de dados não otimizadas.
Ferramentas: Prometheus Node Exporter para métricas de SO, instrumentação manual de código para métricas de aplicação, ELK para logs.
Em 2026, a observabilidade não é apenas para “resolver problemas”, mas também para otimizar proativamente e entender o impacto de novas funcionalidades. Ao integrar observabilidade no ciclo de vida de desenvolvimento, as equipes podem validar hipóteses de desempenho, testar o impacto de novas features antes do lançamento e garantir que as mudanças não introduzam regressões. É a ponte entre a engenharia e o valor de negócio, fornecendo os dados necessários para tomar decisões informadas.
Perguntas Frequentes sobre Observabilidade
Q. Qual a diferença entre monitoramento e observabilidade?
Monitoramento foca em saber se o sistema está funcionando (métricas conhecidas). Observabilidade é a capacidade de entender por que o sistema não está funcionando, inferindo seu estado interno a partir de métricas, logs e traces, permitindo explorar problemas desconhecidos.
Q. Por que o OpenTelemetry é tão importante em 2026?
O OpenTelemetry se tornou o padrão para instrumentação, oferecendo uma API unificada e agnóstica de fornecedor para coletar métricas, logs e traces. Ele elimina o “vendor lock-in”, simplifica a instrumentação e permite trocar facilmente de backend de observabilidade sem reescrever o código.
Q. Como posso começar a implementar observabilidade em um sistema legado?
Comece adicionando métricas de infraestrutura (CPU, memória) e logs estruturados em pontos críticos. Em seguida, adicione métricas de aplicação para endpoints chave. Se possível, introduza o tracing para as operações mais importantes, mesmo que não seja distribuído em todo o monólito, para identificar gargalos internos.
Q. Quais são os principais desafios de custo na observabilidade?
Os custos de armazenamento e ingestão de dados são os maiores desafios, especialmente com logs e traces de alta cardinalidade. Estratégias como amostragem (sampling) para traces, agregação de métricas e gerenciamento inteligente de rótulos são cruciais para controlar os gastos sem perder a visibilidade essencial.
Obrigado por ler!
Esperamos que este guia completo tenha iluminado o caminho para uma observabilidade mais robusta em seus sistemas distribuídos em 2026. Dominar esses conceitos e ferramentas é essencial para construir e manter aplicações de alta performance e resiliência na complexa paisagem tecnológica atual.
Dúvidas? Deixe um comentário ou explore mais conteúdos em Kwontudo.com!